WorldGPT: Empowering LLM as Multimodal World Model
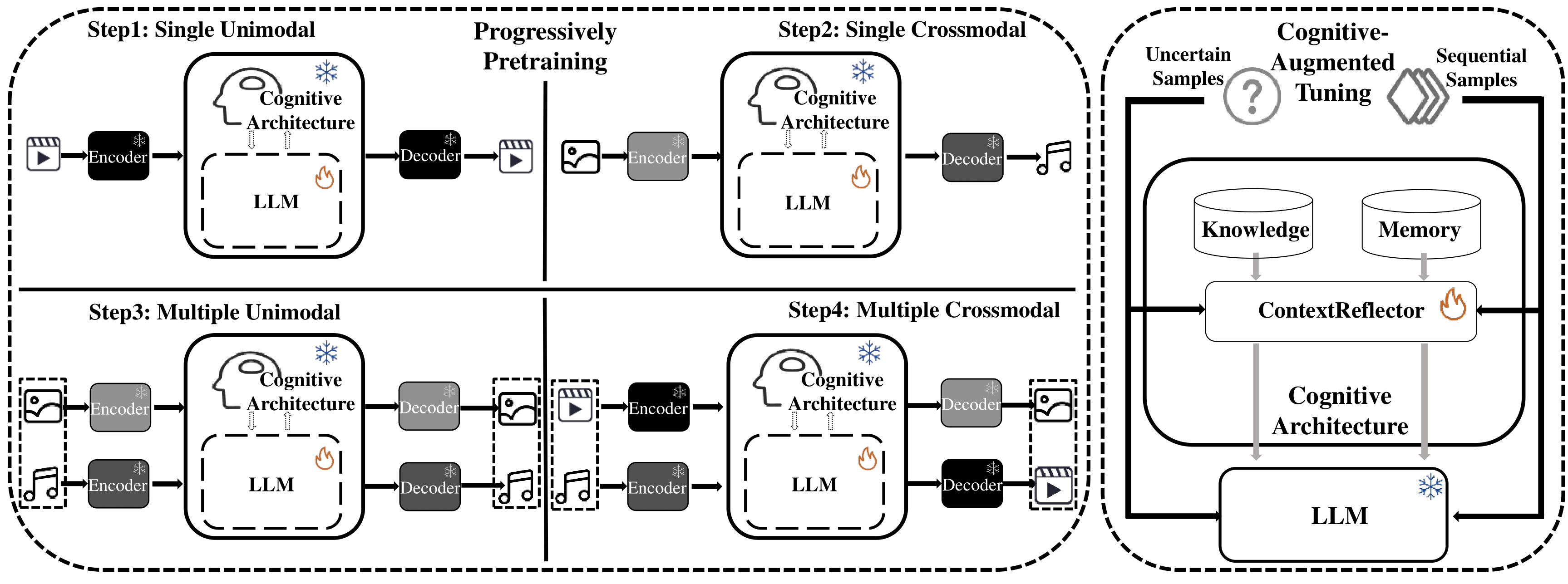
World models are progressively being employed across diverse fields, extending from basic environment simulation to complex scenario construction. However, existing models are mainly trained on domain-specific states and actions, and confined to single-modality state representations. In this paper, We introduce WorldGPT, a generalist world model built upon Multimodal Large Language Model (MLLM). WorldGPT acquires an understanding of world dynamics through analyzing millions of videos across various domains. To further enhance WorldGPT's capability in specialized scenarios and long-term tasks, we have integrated it with a novel cognitive architecture that combines memory offloading, knowledge retrieval, and context reflection. As for evaluation, we build WorldNet, a multimodal state transition prediction benchmark encompassing varied real-life scenarios. Conducting evaluations on WorldNet directly demonstrates WorldGPT's capability to accurately model state transition patterns, affirming its effectiveness in understanding and predicting the dynamics of complex scenarios. We further explore WorldGPT's emerging potential in serving as a world simulator, helping multimodal agents generalize to unfamiliar domains through efficiently synthesising multimodal instruction instances which are proved to be as reliable as authentic data for fine-tuning purposes. The project is available on \url{https://github.com/DCDmllm/WorldGPT}.
PDF Abstract


 Charades
Charades
 Something-Something V2
Something-Something V2
 YouCook2
YouCook2
