VPTR: Efficient Transformers for Video Prediction
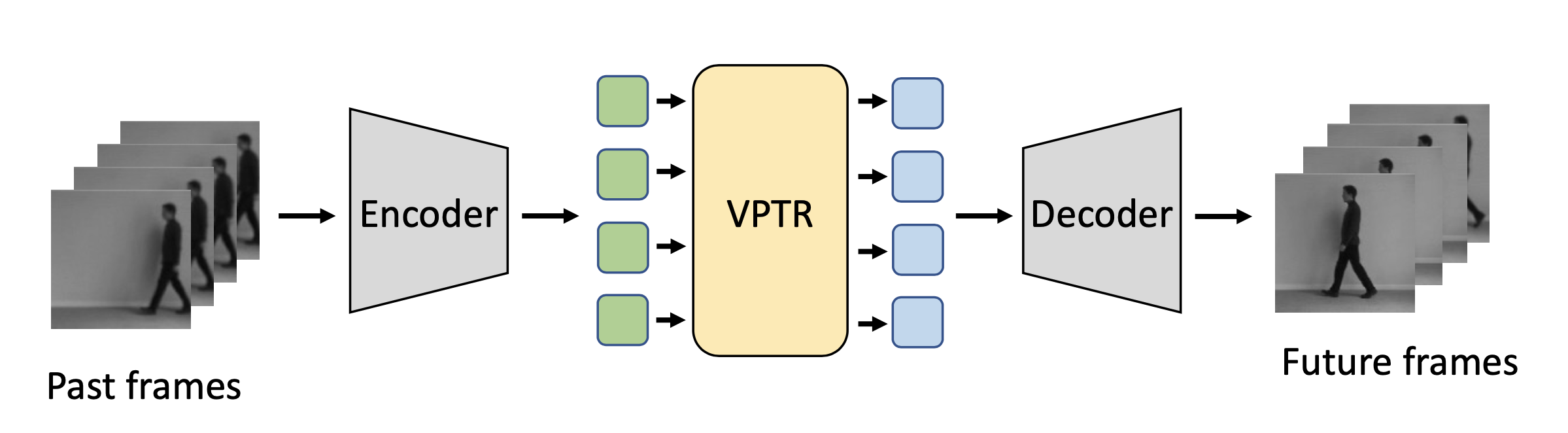
In this paper, we propose a new Transformer block for video future frames prediction based on an efficient local spatial-temporal separation attention mechanism. Based on this new Transformer block, a fully autoregressive video future frames prediction Transformer is proposed. In addition, a non-autoregressive video prediction Transformer is also proposed to increase the inference speed and reduce the accumulated inference errors of its autoregressive counterpart. In order to avoid the prediction of very similar future frames, a contrastive feature loss is applied to maximize the mutual information between predicted and ground-truth future frame features. This work is the first that makes a formal comparison of the two types of attention-based video future frames prediction models over different scenarios. The proposed models reach a performance competitive with more complex state-of-the-art models. The source code is available at \emph{https://github.com/XiYe20/VPTR}.
PDF Abstract

 KTH
KTH
 Moving MNIST
Moving MNIST
