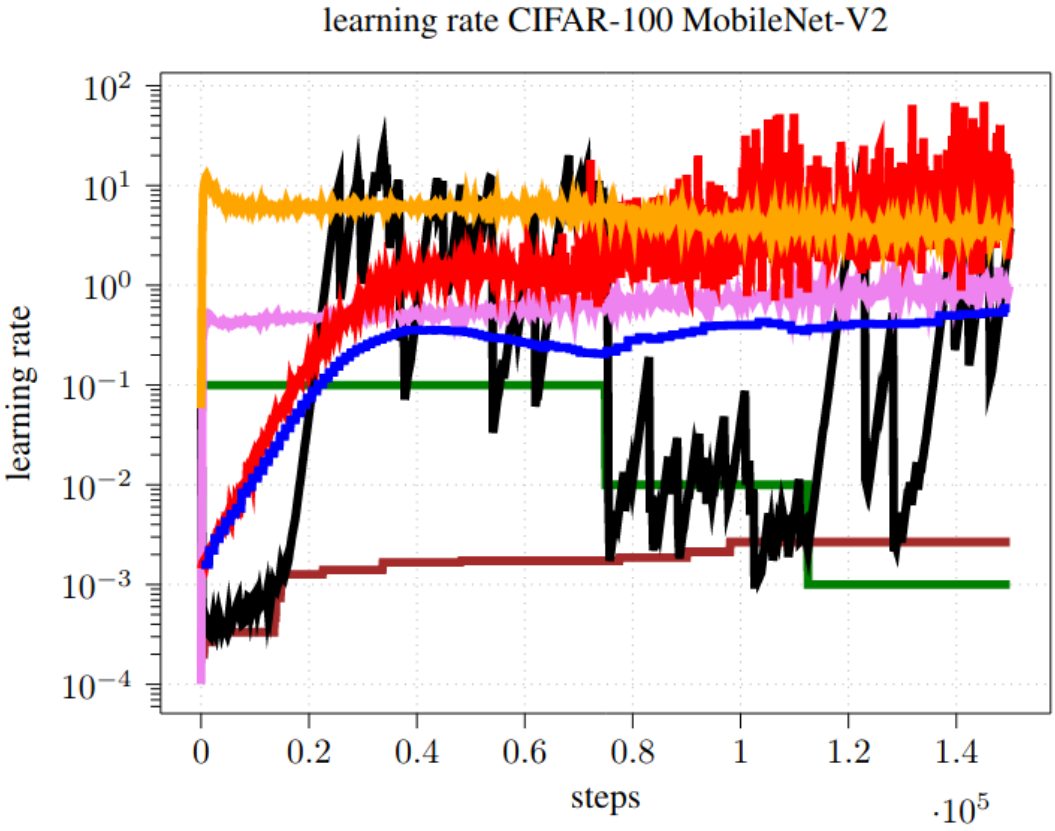
Using a one dimensional parabolic model of the full-batch loss to estimate learning rates during training
A fundamental challenge in Deep Learning is to find optimal step sizes for stochastic gradient descent automatically. In traditional optimization, line searches are a commonly used method to determine step sizes. One problem in Deep Learning is that finding appropriate step sizes on the full-batch loss is unfeasibly expensive. Therefore, classical line search approaches, designed for losses without inherent noise, are usually not applicable. Recent empirical findings suggest, inter alia, that the full-batch loss behaves locally parabolically in the direction of noisy update step directions. Furthermore, the trend of the optimal update step size changes slowly. By exploiting these and more findings, this work introduces a line-search method that approximates the full-batch loss with a parabola estimated over several mini-batches. Learning rates are derived from such parabolas during training. In the experiments conducted, our approach is on par with SGD with Momentum tuned with a piece-wise constant learning rate schedule and often outperforms other line search approaches for Deep Learning across models, datasets, and batch sizes on validation and test accuracy. In addition, our approach is the first line search approach for Deep Learning that samples a larger batch size over multiple inferences to still work in low-batch scenarios.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 SVHN
SVHN
