Unsupervised Video Summarization via Multi-source Features
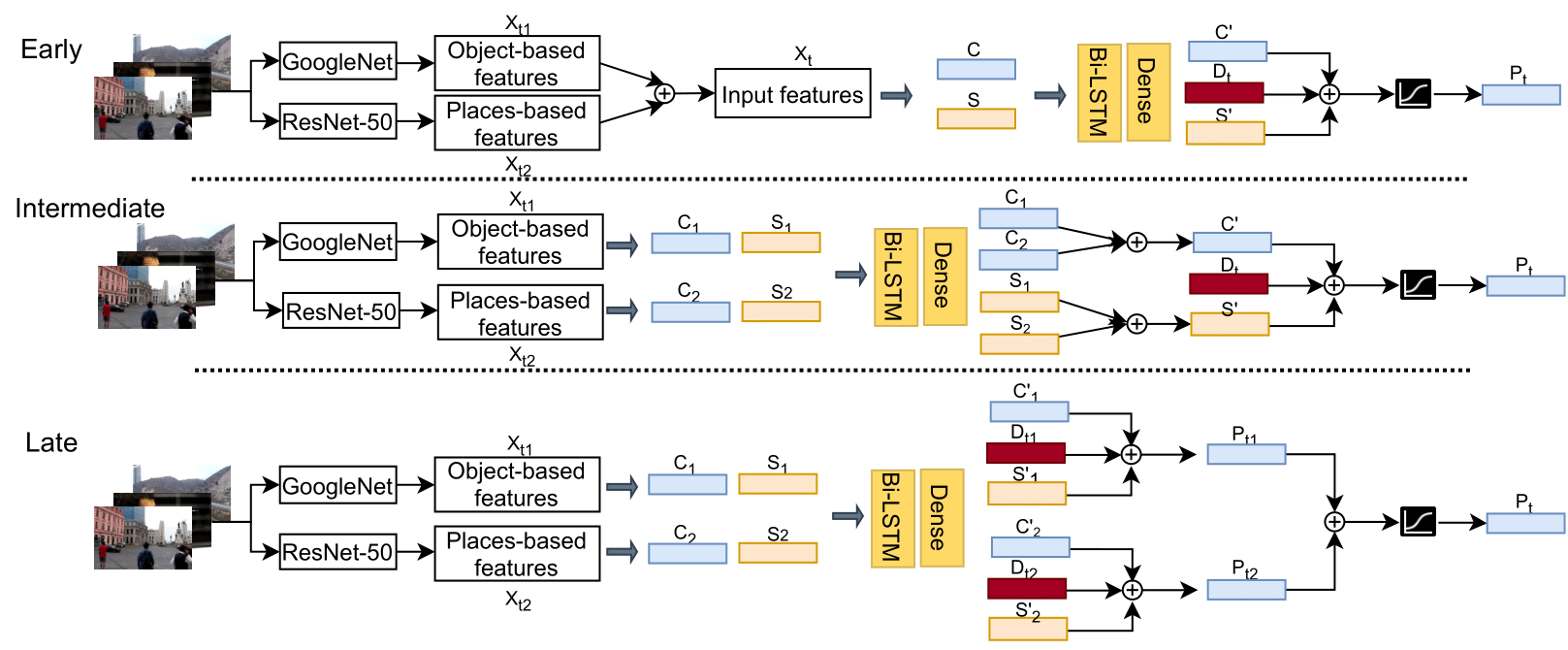
Video summarization aims at generating a compact yet representative visual summary that conveys the essence of the original video. The advantage of unsupervised approaches is that they do not require human annotations to learn the summarization capability and generalize to a wider range of domains. Previous work relies on the same type of deep features, typically based on a model pre-trained on ImageNet data. Therefore, we propose the incorporation of multiple feature sources with chunk and stride fusion to provide more information about the visual content. For a comprehensive evaluation on the two benchmarks TVSum and SumMe, we compare our method with four state-of-the-art approaches. Two of these approaches were implemented by ourselves to reproduce the reported results. Our evaluation shows that we obtain state-of-the-art results on both datasets, while also highlighting the shortcomings of previous work with regard to the evaluation methodology. Finally, we perform error analysis on videos for the two benchmark datasets to summarize and spot the factors that lead to misclassifications.
PDF Abstract


 Places
Places
 SumMe
SumMe
