Unsupervised multi-latent space reinforcement learning framework for video summarization in ultrasound imaging
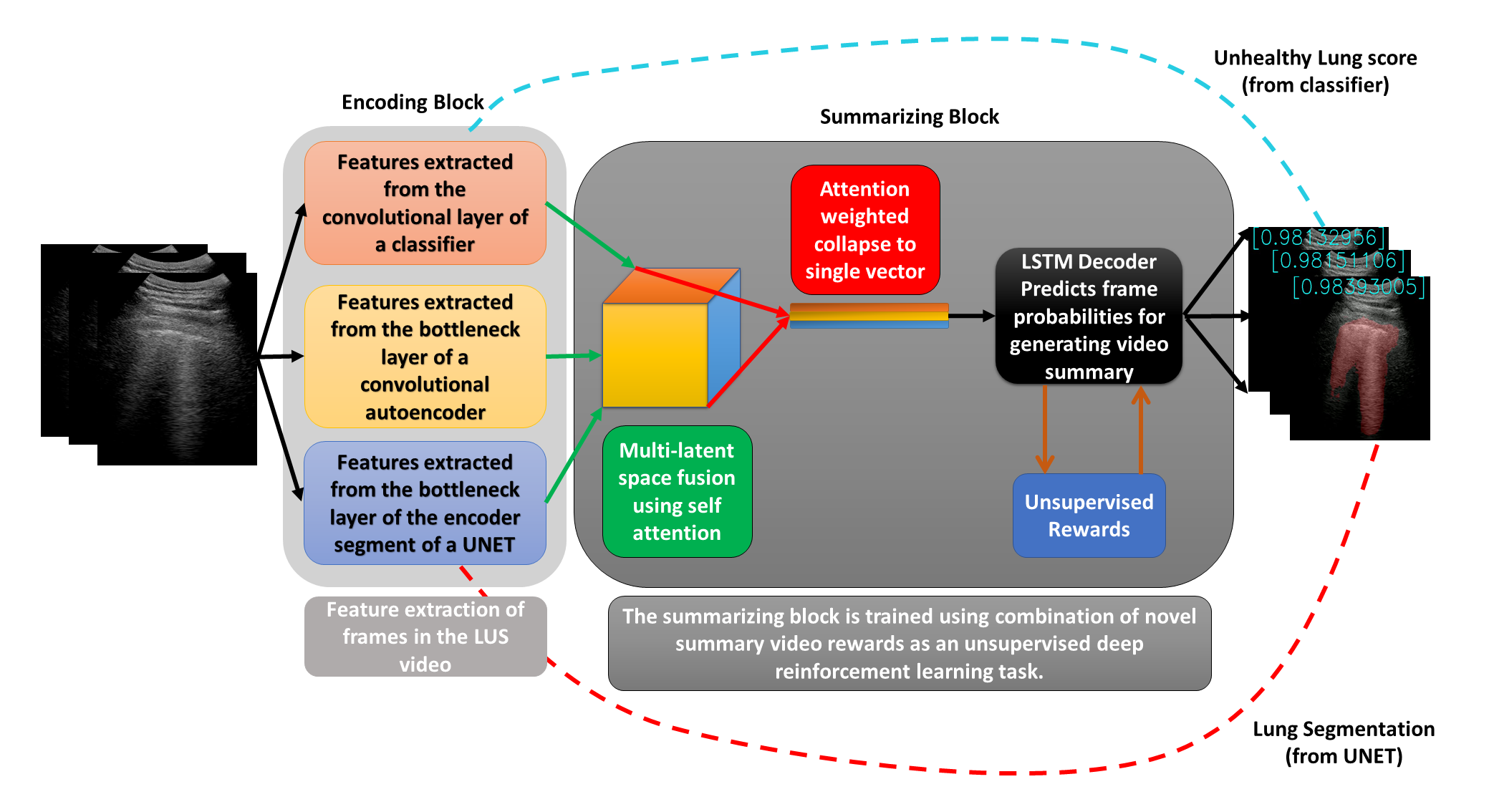
The COVID-19 pandemic has highlighted the need for a tool to speed up triage in ultrasound scans and provide clinicians with fast access to relevant information. The proposed video-summarization technique is a step in this direction that provides clinicians access to relevant key-frames from a given ultrasound scan (such as lung ultrasound) while reducing resource, storage and bandwidth requirements. We propose a new unsupervised reinforcement learning (RL) framework with novel rewards that facilitates unsupervised learning avoiding tedious and impractical manual labelling for summarizing ultrasound videos to enhance its utility as a triage tool in the emergency department (ED) and for use in telemedicine. Using an attention ensemble of encoders, the high dimensional image is projected into a low dimensional latent space in terms of: a) reduced distance with a normal or abnormal class (classifier encoder), b) following a topology of landmarks (segmentation encoder), and c) the distance or topology agnostic latent representation (convolutional autoencoders). The decoder is implemented using a bi-directional long-short term memory (Bi-LSTM) which utilizes the latent space representation from the encoder. Our new paradigm for video summarization is capable of delivering classification labels and segmentation of key landmarks for each of the summarized keyframes. Validation is performed on lung ultrasound (LUS) dataset, that typically represent potential use cases in telemedicine and ED triage acquired from different medical centers across geographies (India, Spain and Canada).
PDF Abstract


