Understanding Catastrophic Forgetting in Language Models via Implicit Inference
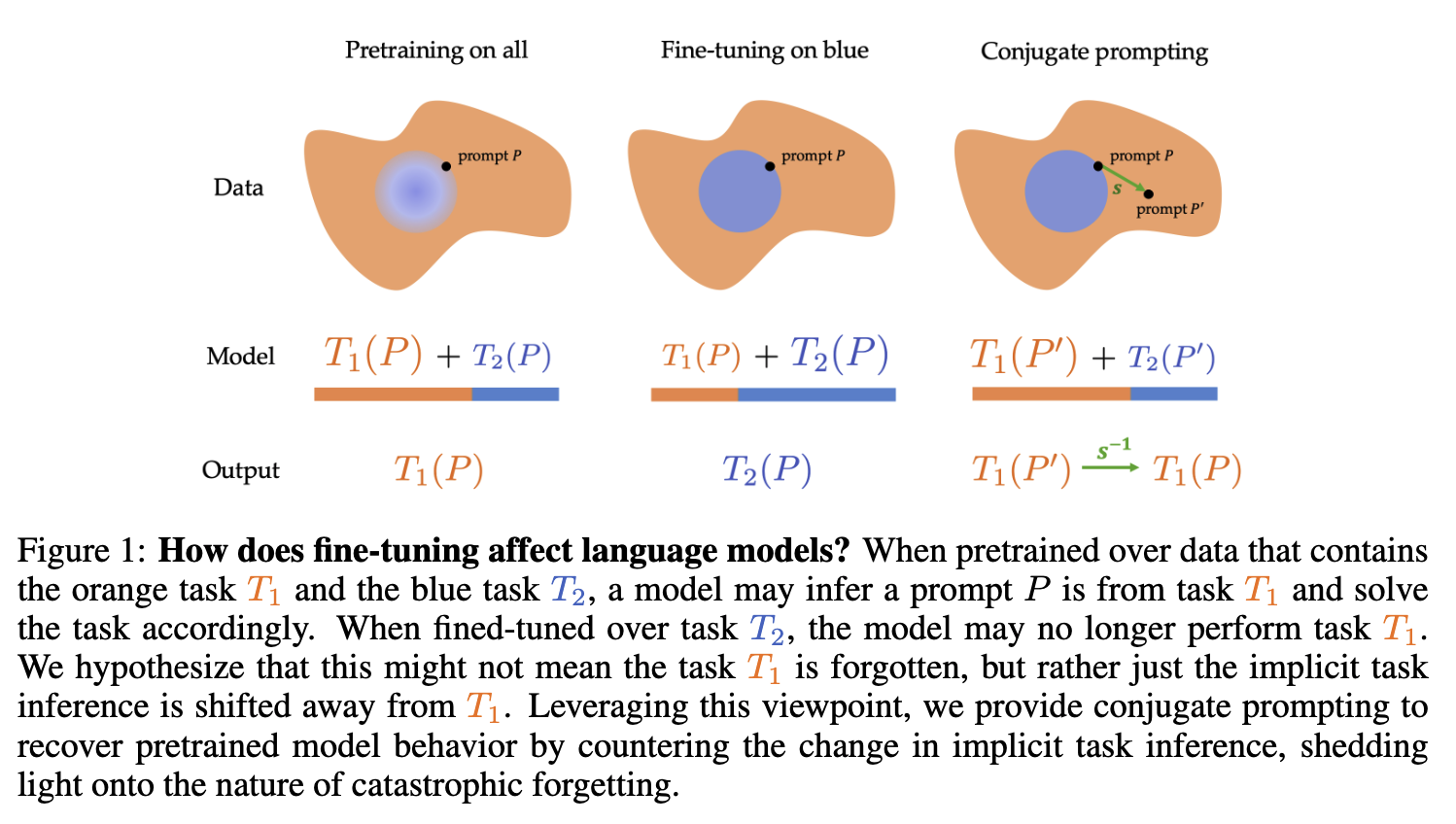
We lack a systematic understanding of the effects of fine-tuning (via methods such as instruction-tuning or reinforcement learning from human feedback), particularly on tasks outside the narrow fine-tuning distribution. In a simplified scenario, we demonstrate that improving performance on tasks within the fine-tuning data distribution comes at the expense of capabilities on other tasks. We hypothesize that language models implicitly infer the task of the prompt and that fine-tuning skews this inference towards tasks in the fine-tuning distribution. To test this, we propose Conjugate Prompting, which artificially makes the task look farther from the fine-tuning distribution while requiring the same capability, and we find that this recovers some of the pretraining capabilities in our synthetic setup. Since real-world fine-tuning distributions are predominantly English, we apply conjugate prompting to recover pretrained capabilities in LLMs by simply translating the prompts to different languages. This allows us to recover in-context learning abilities lost via instruction tuning, natural reasoning capability lost during code fine-tuning, and, more concerningly, harmful content generation suppressed by safety fine-tuning in chatbots like ChatGPT.
PDF Abstract
 MultiNLI
MultiNLI
 XNLI
XNLI
