Textual Relationship Modeling for Cross-Modal Information Retrieval
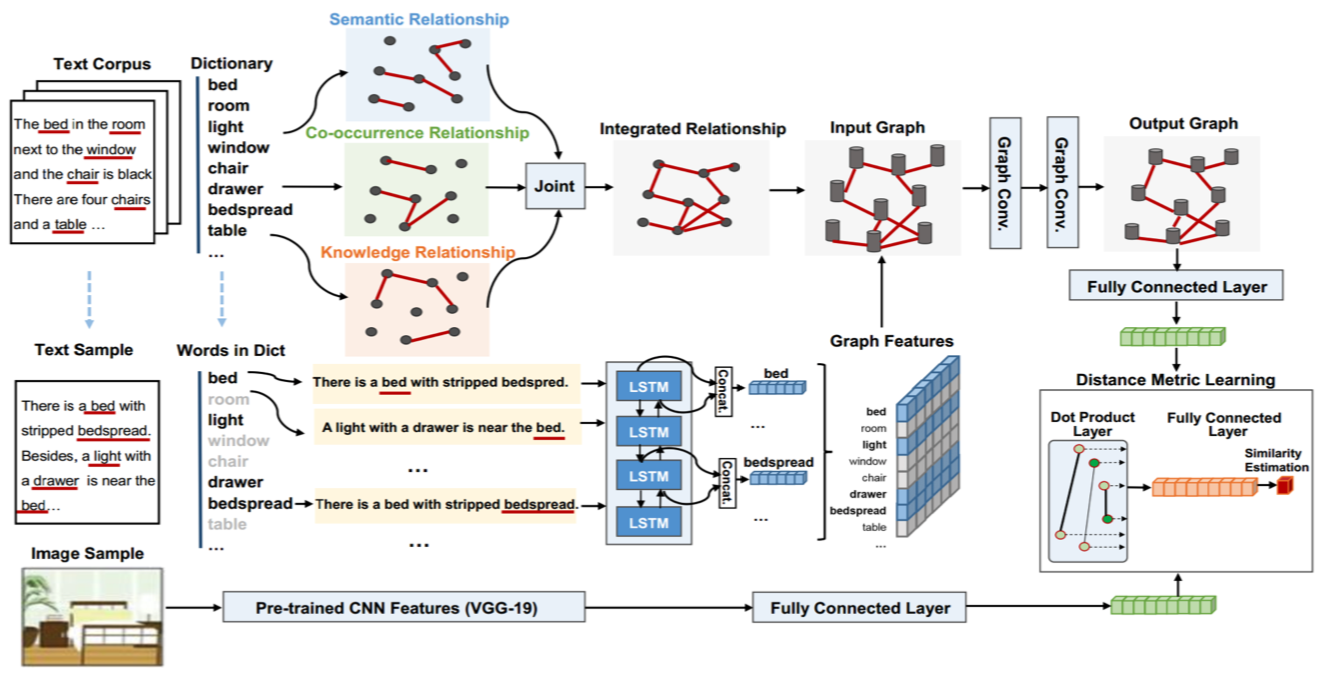
Feature representation of different modalities is the main focus of current cross-modal information retrieval research. Existing models typically project texts and images into the same embedding space. In this paper, we explore the multitudinous of textural relationships in text modeling. Specifically, texts are represented by a graph generated using various textural relationships including semantic relations, statistical co-occurrence, and predefined knowledge base. A joint neural model is proposed to learn feature representation individually in each modality. We use Graph Convolutional Network (GCN) to capture relation-aware representations of texts and Convolutional Neural Network (CNN) to learn image representations. Comprehensive experiments are conducted on two benchmark datasets. The results show that our model outperforms the state-of-the-art models significantly by 6.3% on the CMPlaces data and 3.4% on English Wikipedia, respectively.
PDF Abstract
