Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion
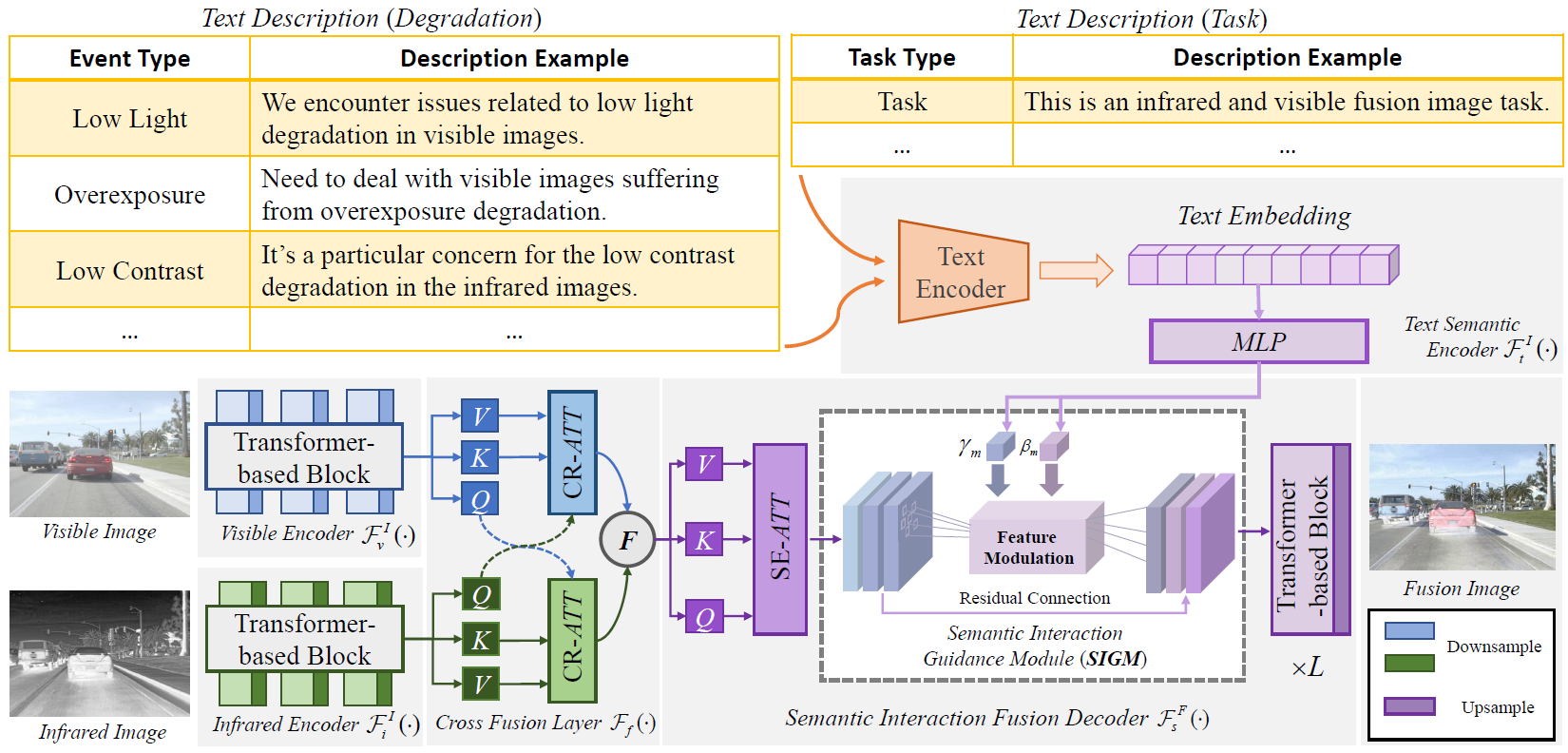
Image fusion aims to combine information from different source images to create a comprehensively representative image. Existing fusion methods are typically helpless in dealing with degradations in low-quality source images and non-interactive to multiple subjective and objective needs. To solve them, we introduce a novel approach that leverages semantic text guidance image fusion model for degradation-aware and interactive image fusion task, termed as Text-IF. It innovatively extends the classical image fusion to the text guided image fusion along with the ability to harmoniously address the degradation and interaction issues during fusion. Through the text semantic encoder and semantic interaction fusion decoder, Text-IF is accessible to the all-in-one infrared and visible image degradation-aware processing and the interactive flexible fusion outcomes. In this way, Text-IF achieves not only multi-modal image fusion, but also multi-modal information fusion. Extensive experiments prove that our proposed text guided image fusion strategy has obvious advantages over SOTA methods in the image fusion performance and degradation treatment. The code is available at https://github.com/XunpengYi/Text-IF.
PDF Abstract

 LLVIP
LLVIP
