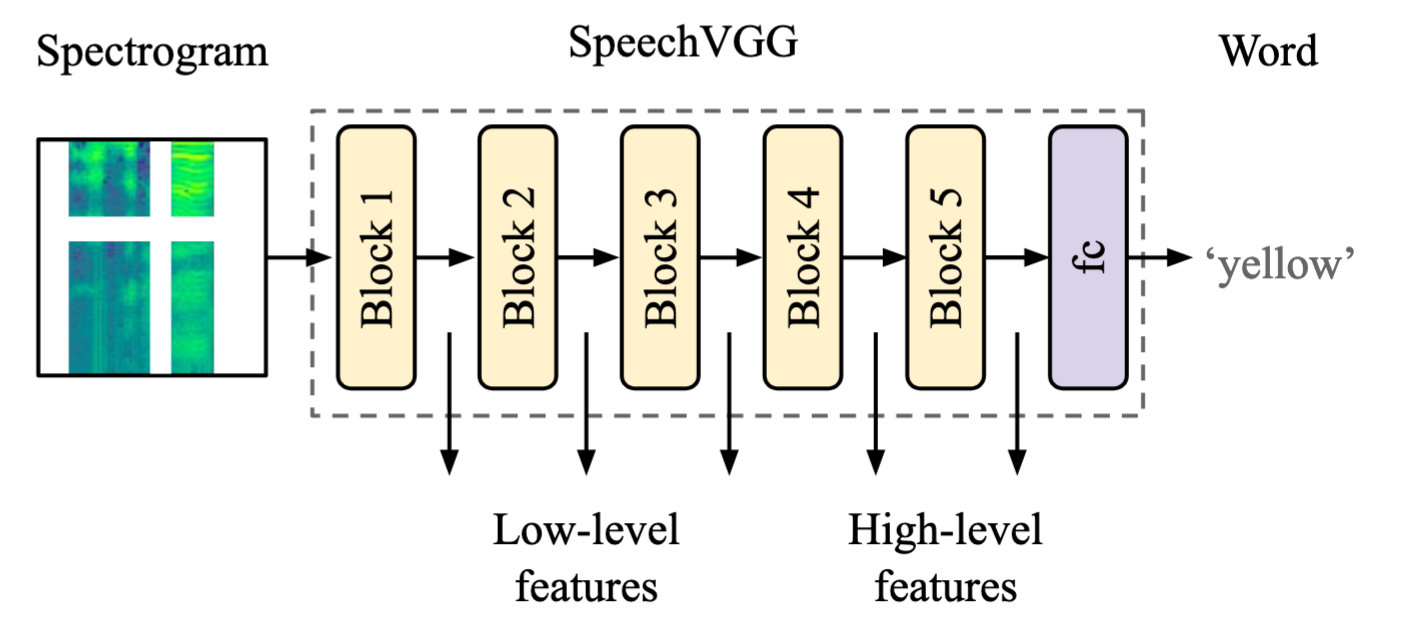
Word-level Embeddings for Cross-Task Transfer Learning in Speech Processing
Recent breakthroughs in deep learning often rely on representation learning and knowledge transfer. In recent years, unsupervised and self-supervised techniques for learning speech representation were developed to foster automatic speech recognition. Up to date, most of these approaches are task-specific and designed for within-task transfer learning between different datasets or setups of a particular task. In turn, learning task-independent representation of speech and cross-task applications of transfer learning remain less common. Here, we introduce an encoder capturing word-level representations of speech for cross-task transfer learning. We demonstrate the application of the pre-trained encoder in four distinct speech and audio processing tasks: (i) speech enhancement, (ii) language identification, (iii) speech, noise, and music classification, and (iv) speaker identification. In each task, we compare the performance of our cross-task transfer learning approach to task-specific baselines. Our results show that the speech representation captured by the encoder through the pre-training is transferable across distinct speech processing tasks and datasets. Notably, even simple applications of our pre-trained encoder outperformed task-specific methods, or were comparable, depending on the task.
PDF Abstract





 LibriSpeech
LibriSpeech
