Single Deep Counterfactual Regret Minimization
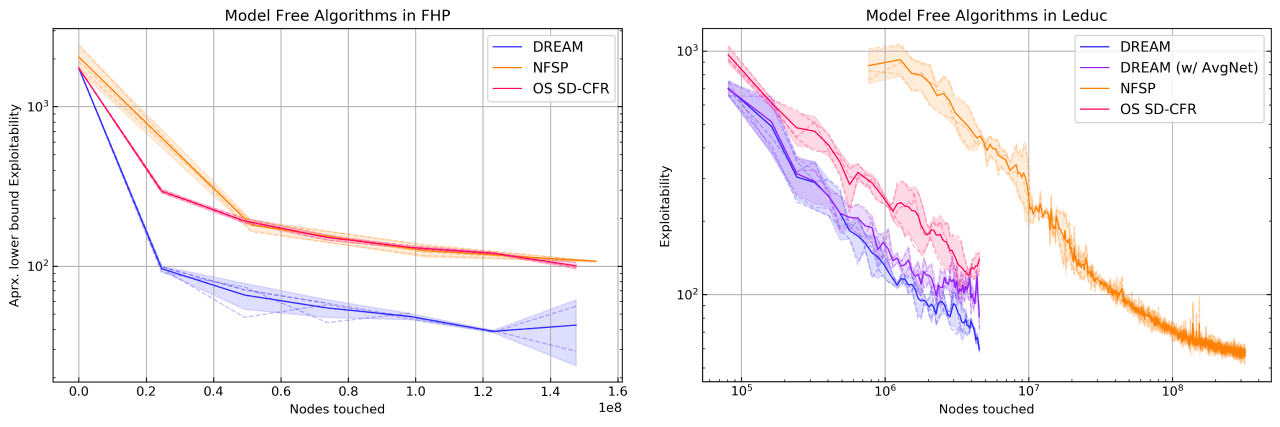
Counterfactual Regret Minimization (CFR) is the most successful algorithm for finding approximate Nash equilibria in imperfect information games. However, CFR's reliance on full game-tree traversals limits its scalability. For this reason, the game's state- and action-space is often abstracted (i.e. simplified) for CFR, and the resulting strategy is then translated back to the full game, which requires extensive expert-knowledge and often converges to highly exploitable policies. A recently proposed method, Deep CFR, applies deep learning directly to CFR, allowing the agent to intrinsically abstract and generalize over the state-space from samples, without requiring expert knowledge. In this paper, we introduce Single Deep CFR (SD-CFR), a simplified variant of Deep CFR that has a lower overall approximation error by avoiding the training of an average strategy network. We show that SD-CFR is more attractive from a theoretical perspective and empirically outperforms Deep CFR with respect to exploitability and one-on-one play in poker.
PDF Abstract

