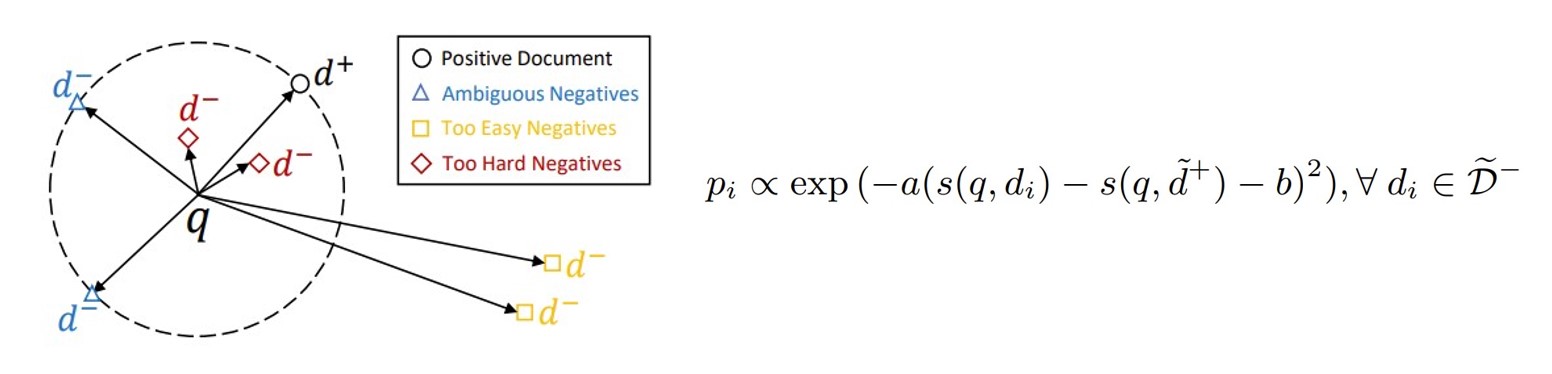
SimANS: Simple Ambiguous Negatives Sampling for Dense Text Retrieval
Sampling proper negatives from a large document pool is vital to effectively train a dense retrieval model. However, existing negative sampling strategies suffer from the uninformative or false negative problem. In this work, we empirically show that according to the measured relevance scores, the negatives ranked around the positives are generally more informative and less likely to be false negatives. Intuitively, these negatives are not too hard (\emph{may be false negatives}) or too easy (\emph{uninformative}). They are the ambiguous negatives and need more attention during training. Thus, we propose a simple ambiguous negatives sampling method, SimANS, which incorporates a new sampling probability distribution to sample more ambiguous negatives. Extensive experiments on four public and one industry datasets show the effectiveness of our approach. We made the code and models publicly available in \url{https://github.com/microsoft/SimXNS}.
PDF Abstract

 Natural Questions
Natural Questions
 MS MARCO
MS MARCO
