SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension
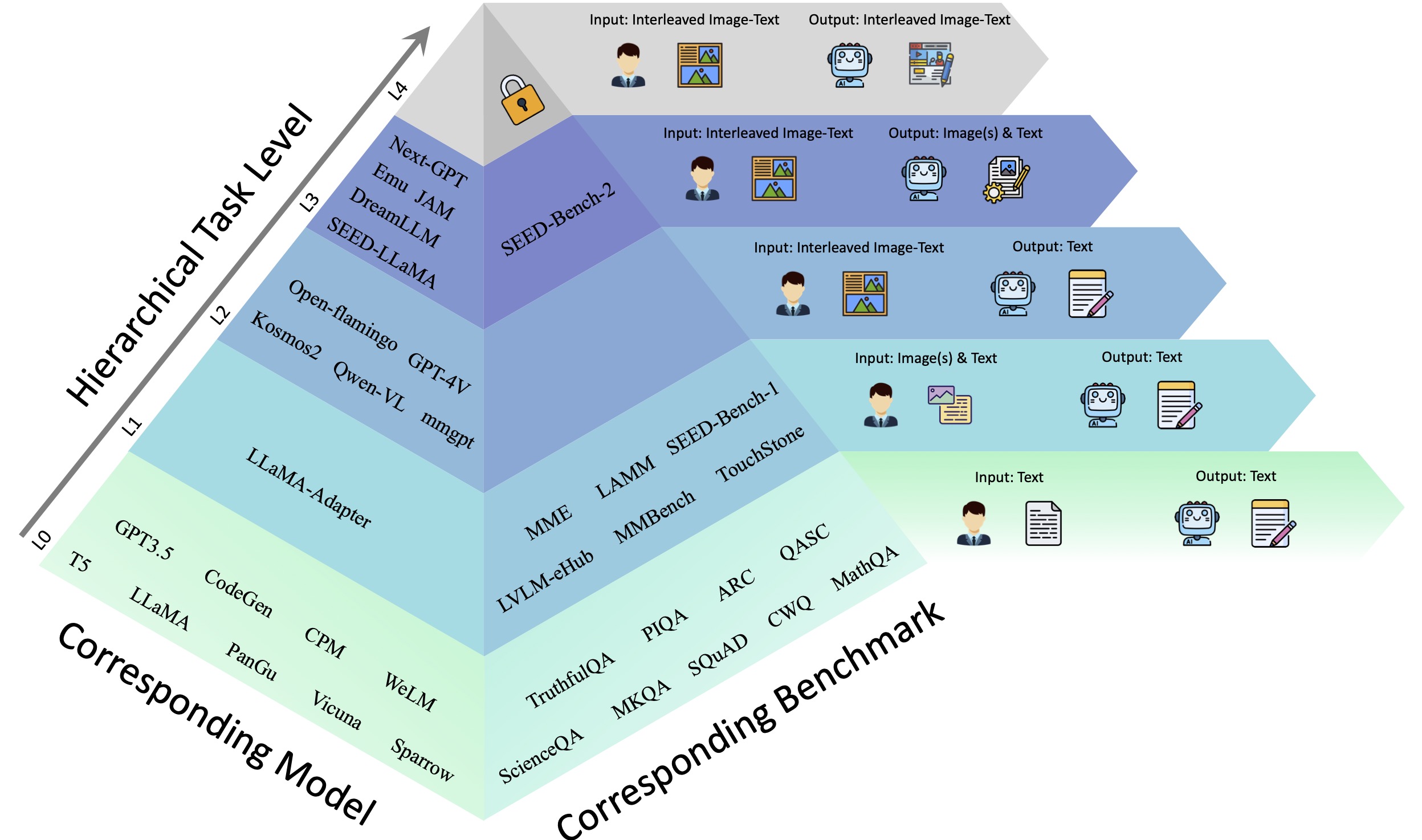
Comprehending text-rich visual content is paramount for the practical application of Multimodal Large Language Models (MLLMs), since text-rich scenarios are ubiquitous in the real world, which are characterized by the presence of extensive texts embedded within images. Recently, the advent of MLLMs with impressive versatility has raised the bar for what we can expect from MLLMs. However, their proficiency in text-rich scenarios has yet to be comprehensively and objectively assessed, since current MLLM benchmarks primarily focus on evaluating general visual comprehension. In this work, we introduce SEED-Bench-2-Plus, a benchmark specifically designed for evaluating \textbf{text-rich visual comprehension} of MLLMs. Our benchmark comprises 2.3K multiple-choice questions with precise human annotations, spanning three broad categories: Charts, Maps, and Webs, each of which covers a wide spectrum of text-rich scenarios in the real world. These categories, due to their inherent complexity and diversity, effectively simulate real-world text-rich environments. We further conduct a thorough evaluation involving 34 prominent MLLMs (including GPT-4V, Gemini-Pro-Vision and Claude-3-Opus) and emphasize the current limitations of MLLMs in text-rich visual comprehension. We hope that our work can serve as a valuable addition to existing MLLM benchmarks, providing insightful observations and inspiring further research in the area of text-rich visual comprehension with MLLMs. The dataset and evaluation code can be accessed at https://github.com/AILab-CVC/SEED-Bench.
PDF Abstract Spaces
Spaces


 MMBench
MMBench
 SEED-Bench
SEED-Bench
