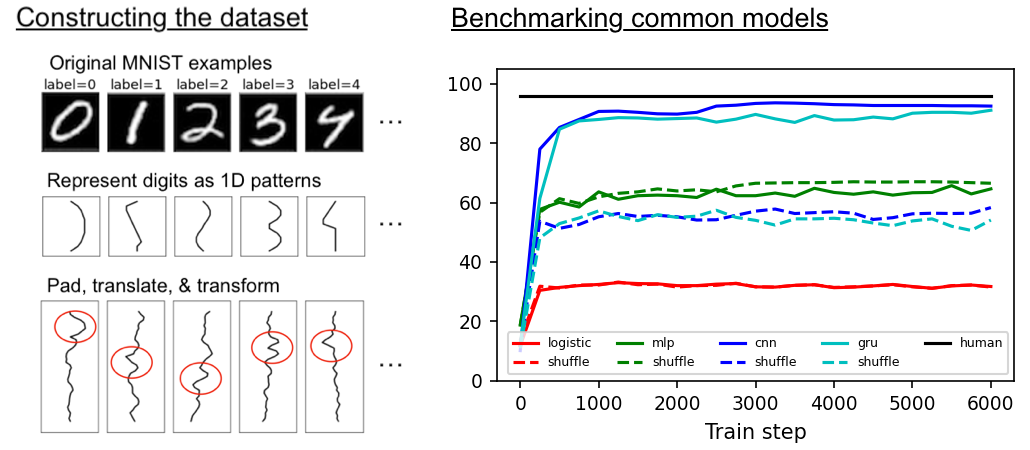
Scaling Down Deep Learning with MNIST-1D
Although deep learning models have taken on commercial and political relevance, key aspects of their training and operation remain poorly understood. This has sparked interest in science of deep learning projects, many of which require large amounts of time, money, and electricity. But how much of this research really needs to occur at scale? In this paper, we introduce MNIST-1D: a minimalist, procedurally generated, low-memory, and low-compute alternative to classic deep learning benchmarks. Although the dimensionality of MNIST-1D is only 40 and its default training set size only 4000, MNIST-1D can be used to study inductive biases of different deep architectures, find lottery tickets, observe deep double descent, metalearn an activation function, and demonstrate guillotine regularization in self-supervised learning. All these experiments can be conducted on a GPU or often even on a CPU within minutes, allowing for fast prototyping, educational use cases, and cutting-edge research on a low budget.
PDF Abstract Colab
Colab


 CIFAR-10
CIFAR-10
