Scalable and Efficient Hypothesis Testing with Random Forests
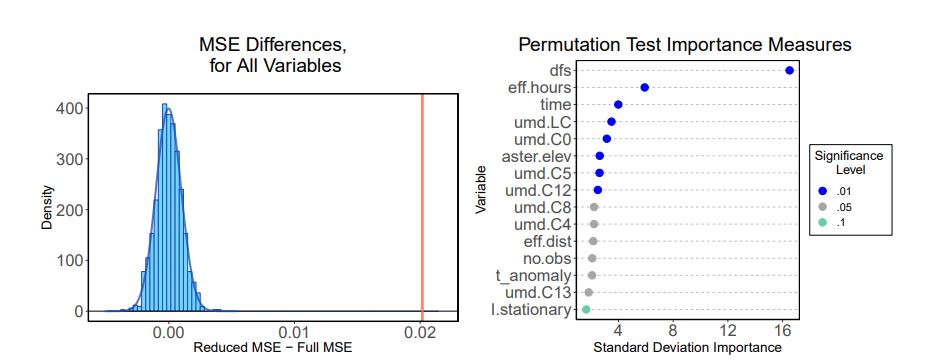
Throughout the last decade, random forests have established themselves as among the most accurate and popular supervised learning methods. While their black-box nature has made their mathematical analysis difficult, recent work has established important statistical properties like consistency and asymptotic normality by considering subsampling in lieu of bootstrapping. Though such results open the door to traditional inference procedures, all formal methods suggested thus far place severe restrictions on the testing framework and their computational overhead precludes their practical scientific use. Here we propose a permutation-style testing approach to formally assess feature significance. We establish asymptotic validity of the test via exchangeability arguments and show that the test maintains high power with orders of magnitude fewer computations. As importantly, the procedure scales easily to big data settings where large training and testing sets may be employed without the need to construct additional models. Simulations and applications to ecological data where random forests have recently shown promise are provided.
PDF Abstract
