ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
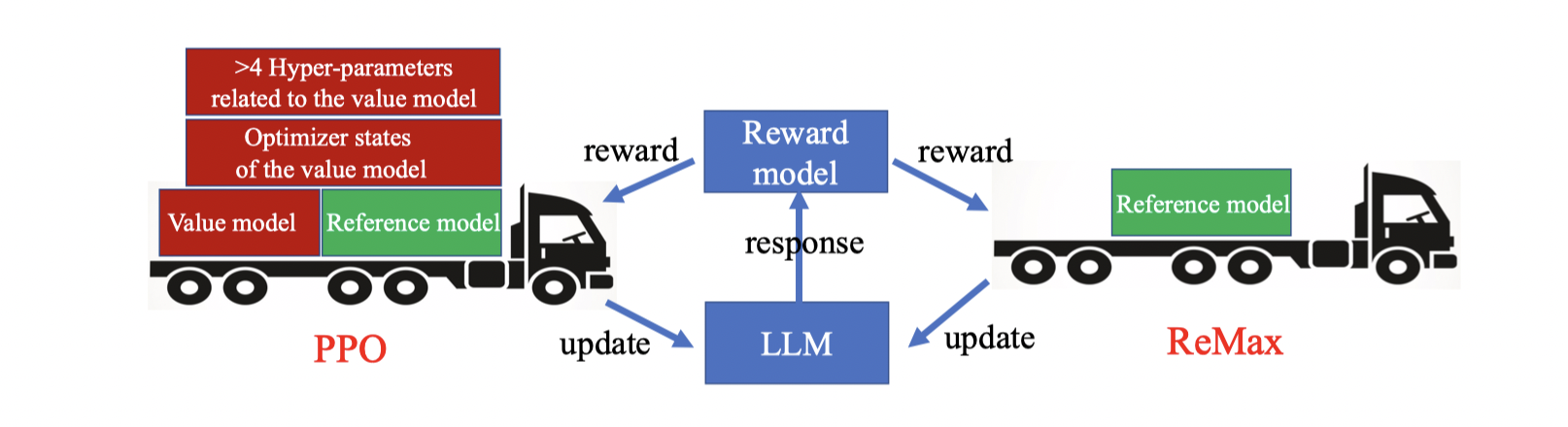
Reinforcement Learning from Human Feedback (RLHF) is key to aligning Large Language Models (LLMs), typically paired with the Proximal Policy Optimization (PPO) algorithm. While PPO is a powerful method designed for general reinforcement learning tasks, it is overly sophisticated for LLMs, leading to laborious hyper-parameter tuning and significant computation burdens. To make RLHF efficient, we present ReMax, which leverages 3 properties of RLHF: fast simulation, deterministic transitions, and trajectory-level rewards. These properties are not exploited in PPO, making it less suitable for RLHF. Building on the renowned REINFORCE algorithm, ReMax does not require training an additional value model as in PPO and is further enhanced with a new variance reduction technique. ReMax offers several benefits over PPO: it is simpler to implement, eliminates more than 4 hyper-parameters in PPO, reduces GPU memory usage, and shortens training time. ReMax can save about 46% GPU memory than PPO when training a 7B model and enables training on A800-80GB GPUs without the memory-saving offloading technique needed by PPO. Applying ReMax to a Mistral-7B model resulted in a 94.78% win rate on the AlpacaEval leaderboard and a 7.739 score on MT-bench, setting a new SOTA for open-source 7B models. These results show the effectiveness of ReMax while addressing the limitations of PPO in LLMs.
PDF Abstract
 AlpacaEval
AlpacaEval
