Prompt Injection Attacks and Defenses in LLM-Integrated Applications
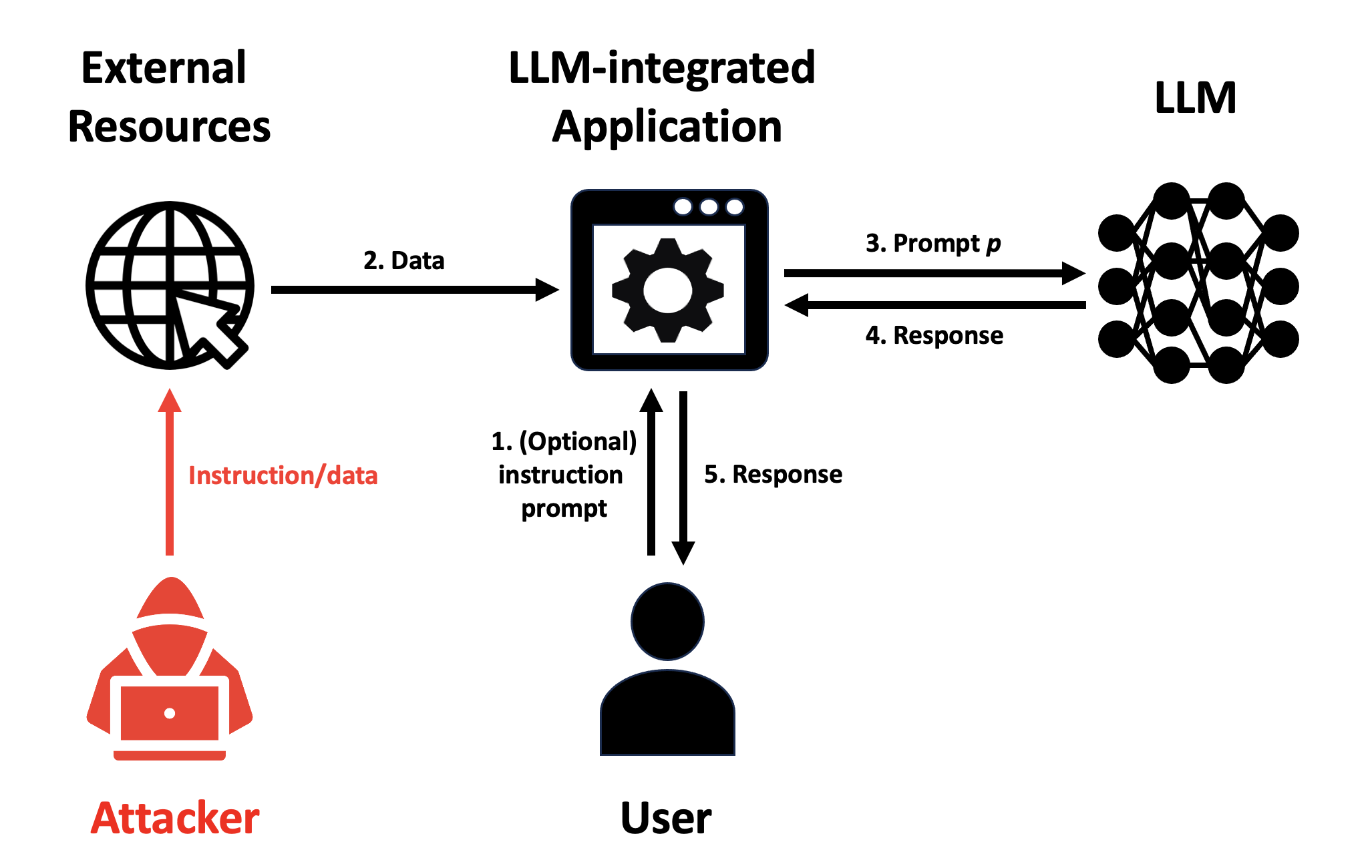
Large Language Models (LLMs) are increasingly deployed as the backend for a variety of real-world applications called LLM-Integrated Applications. Multiple recent works showed that LLM-Integrated Applications are vulnerable to prompt injection attacks, in which an attacker injects malicious instruction/data into the input of those applications such that they produce results as the attacker desires. However, existing works are limited to case studies. As a result, the literature lacks a systematic understanding of prompt injection attacks and their defenses. We aim to bridge the gap in this work. In particular, we propose a general framework to formalize prompt injection attacks. Existing attacks, which are discussed in research papers and blog posts, are special cases in our framework. Our framework enables us to design a new attack by combining existing attacks. Moreover, we also propose a framework to systematize defenses against prompt injection attacks. Using our frameworks, we conduct a systematic evaluation on prompt injection attacks and their defenses with 10 LLMs and 7 tasks. We hope our frameworks can inspire future research in this field. Our code is available at https://github.com/liu00222/Open-Prompt-Injection.
PDF Abstract
 GLUE
GLUE
 SST
SST
