New Benchmark Dataset and Fine-Grained Cross-Modal Fusion Framework for Vietnamese Multimodal Aspect-Category Sentiment Analysis
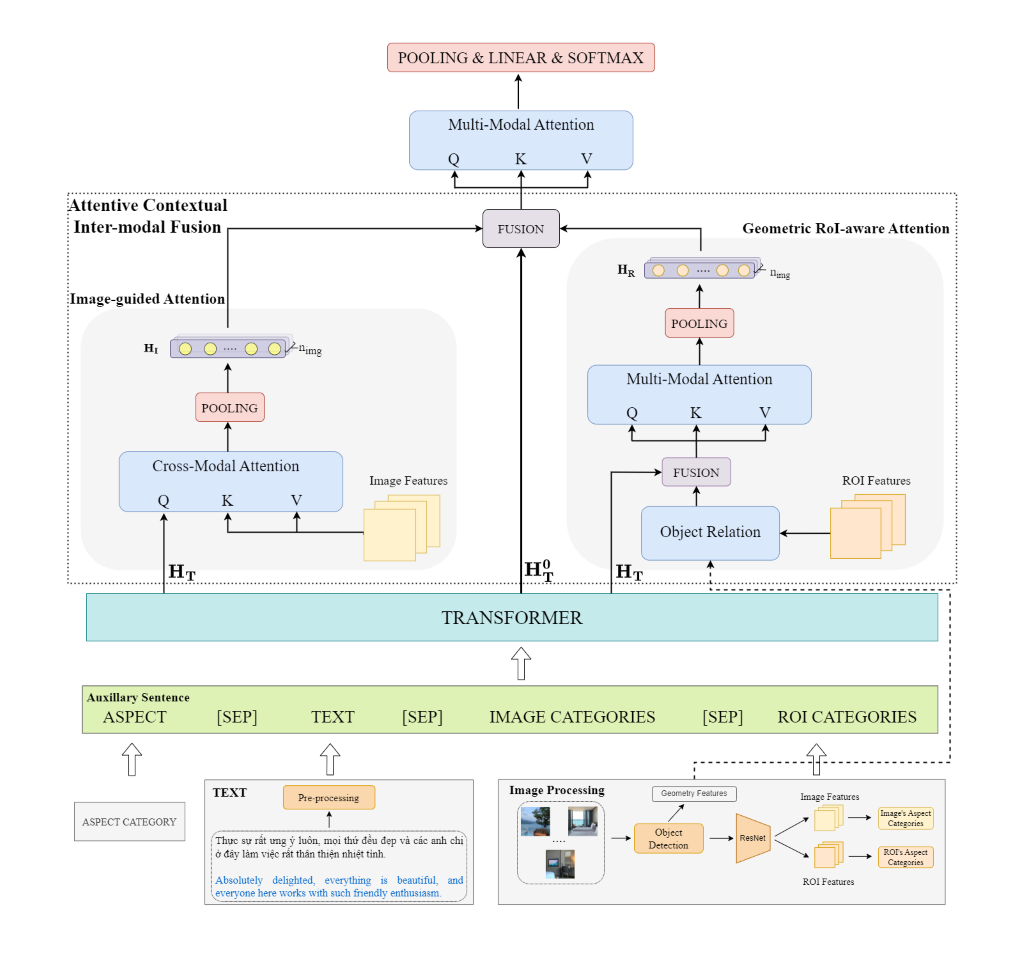
The emergence of multimodal data on social media platforms presents new opportunities to better understand user sentiments toward a given aspect. However, existing multimodal datasets for Aspect-Category Sentiment Analysis (ACSA) often focus on textual annotations, neglecting fine-grained information in images. Consequently, these datasets fail to fully exploit the richness inherent in multimodal. To address this, we introduce a new Vietnamese multimodal dataset, named ViMACSA, which consists of 4,876 text-image pairs with 14,618 fine-grained annotations for both text and image in the hotel domain. Additionally, we propose a Fine-Grained Cross-Modal Fusion Framework (FCMF) that effectively learns both intra- and inter-modality interactions and then fuses these information to produce a unified multimodal representation. Experimental results show that our framework outperforms SOTA models on the ViMACSA dataset, achieving the highest F1 score of 79.73%. We also explore characteristics and challenges in Vietnamese multimodal sentiment analysis, including misspellings, abbreviations, and the complexities of the Vietnamese language. This work contributes both a benchmark dataset and a new framework that leverages fine-grained multimodal information to improve multimodal aspect-category sentiment analysis. Our dataset is available for research purposes: https://github.com/hoangquy18/Multimodal-Aspect-Category-Sentiment-Analysis.
PDF Abstract


