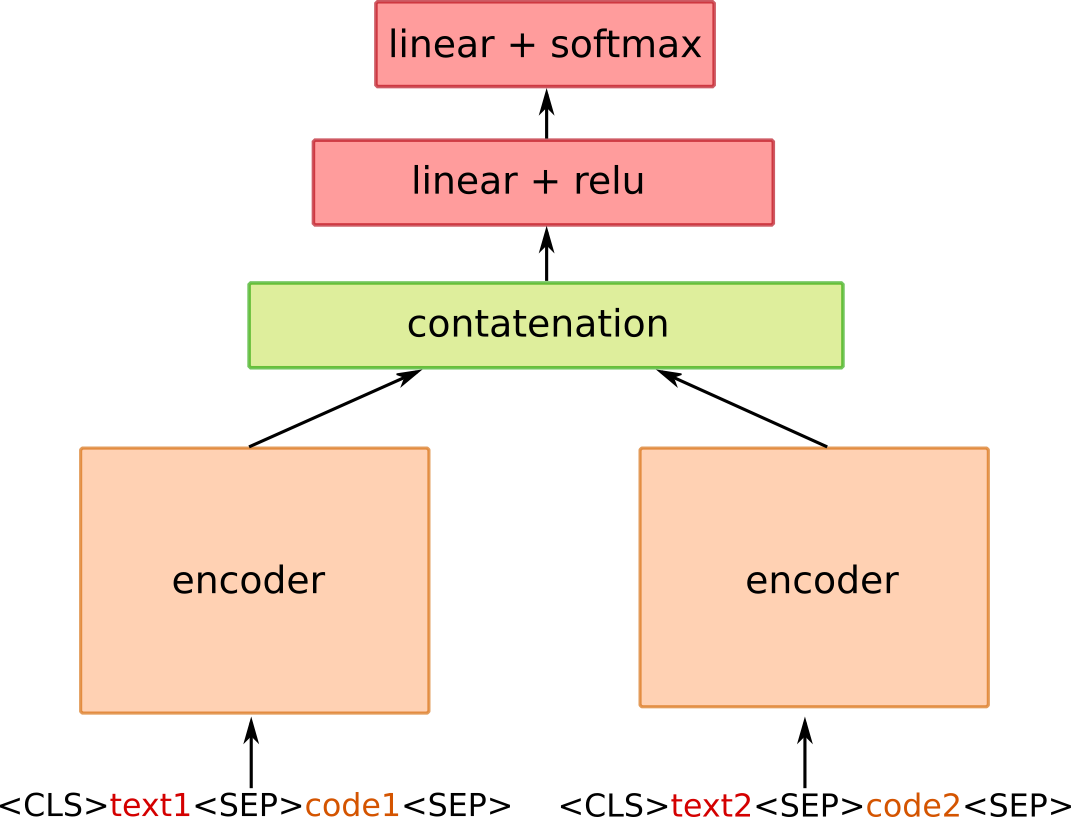
MQDD: Pre-training of Multimodal Question Duplicity Detection for Software Engineering Domain
This work proposes a new pipeline for leveraging data collected on the Stack Overflow website for pre-training a multimodal model for searching duplicates on question answering websites. Our multimodal model is trained on question descriptions and source codes in multiple programming languages. We design two new learning objectives to improve duplicate detection capabilities. The result of this work is a mature, fine-tuned Multimodal Question Duplicity Detection (MQDD) model, ready to be integrated into a Stack Overflow search system, where it can help users find answers for already answered questions. Alongside the MQDD model, we release two datasets related to the software engineering domain. The first Stack Overflow Dataset (SOD) represents a massive corpus of paired questions and answers. The second Stack Overflow Duplicity Dataset (SODD) contains data for training duplicate detection models.
PDF Abstract

