Learning Intrusion Prevention Policies through Optimal Stopping
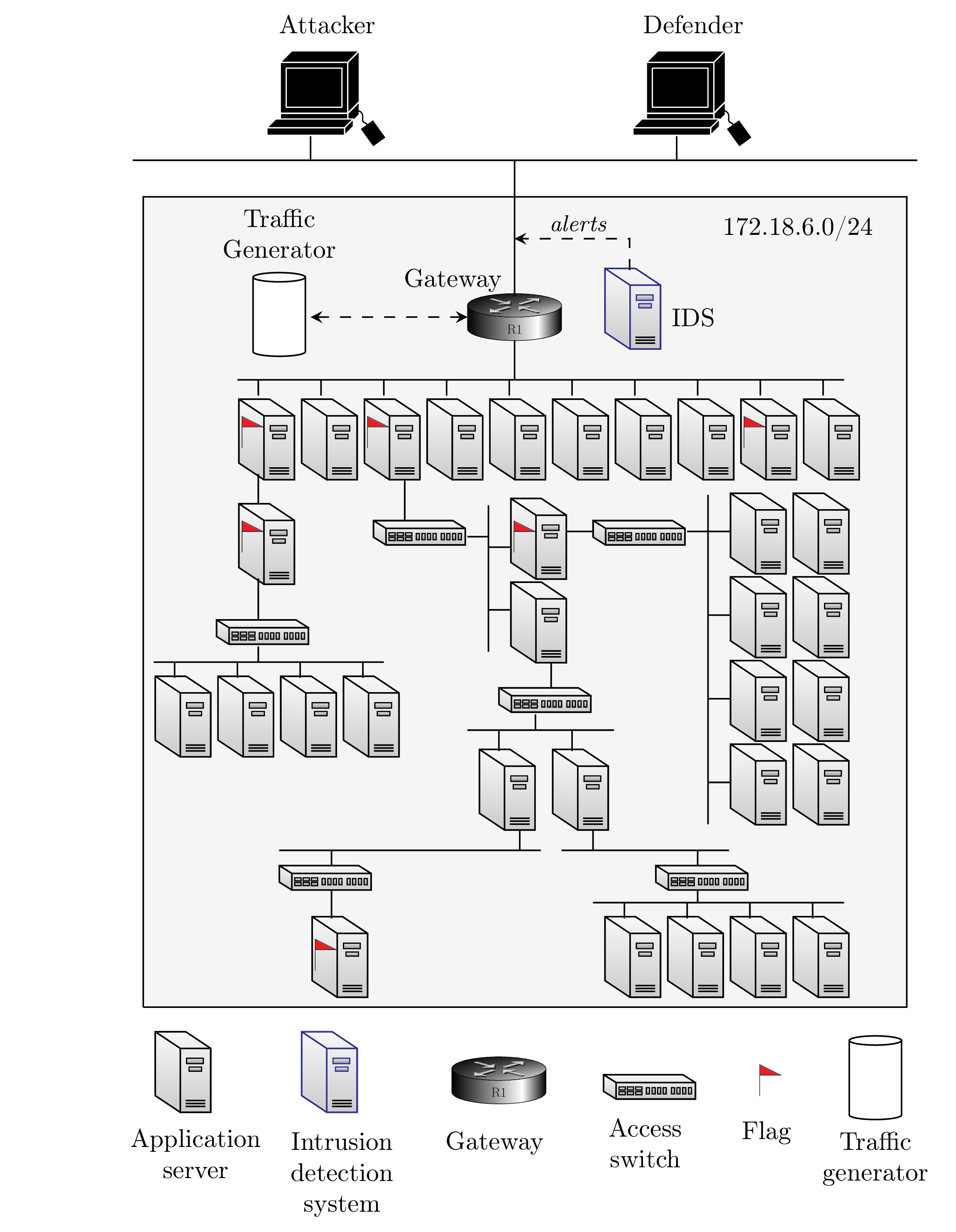
We study automated intrusion prevention using reinforcement learning. In a novel approach, we formulate the problem of intrusion prevention as an optimal stopping problem. This formulation allows us insight into the structure of the optimal policies, which turn out to be threshold based. Since the computation of the optimal defender policy using dynamic programming is not feasible for practical cases, we approximate the optimal policy through reinforcement learning in a simulation environment. To define the dynamics of the simulation, we emulate the target infrastructure and collect measurements. Our evaluations show that the learned policies are close to optimal and that they indeed can be expressed using thresholds.
PDF Abstract

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
