Graph-based Knowledge Distillation by Multi-head Attention Network
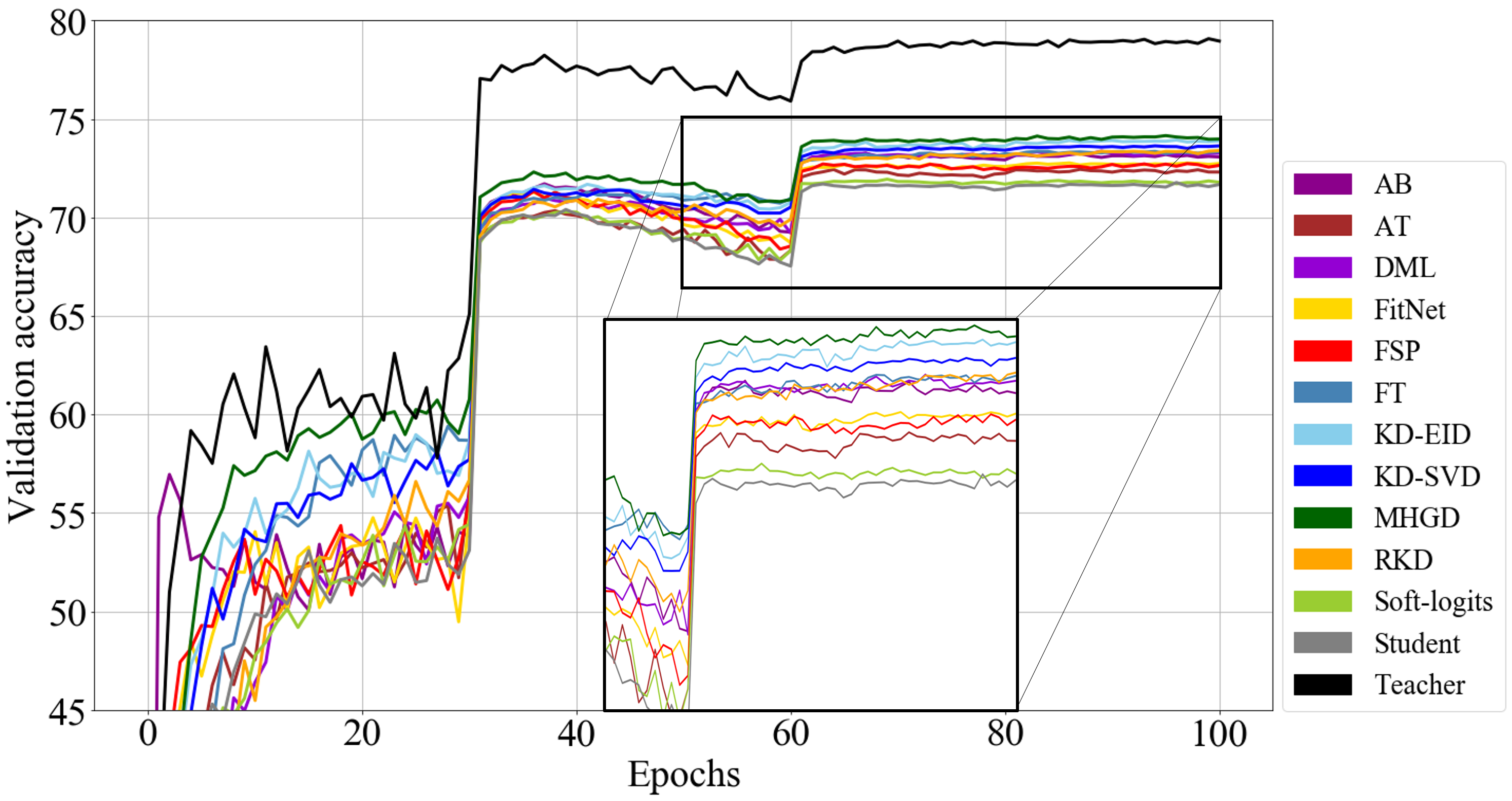
Knowledge distillation (KD) is a technique to derive optimal performance from a small student network (SN) by distilling knowledge of a large teacher network (TN) and transferring the distilled knowledge to the small SN. Since a role of convolutional neural network (CNN) in KD is to embed a dataset so as to perform a given task well, it is very important to acquire knowledge that considers intra-data relations. Conventional KD methods have concentrated on distilling knowledge in data units. To our knowledge, any KD methods for distilling information in dataset units have not yet been proposed. Therefore, this paper proposes a novel method that enables distillation of dataset-based knowledge from the TN using an attention network. The knowledge of the embedding procedure of the TN is distilled to graph by multi-head attention (MHA), and multi-task learning is performed to give relational inductive bias to the SN. The MHA can provide clear information about the source dataset, which can greatly improves the performance of the SN. Experimental results show that the proposed method is 7.05% higher than the SN alone for CIFAR100, which is 2.46% higher than the state-of-the-art.
PDF Abstract



 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
