GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
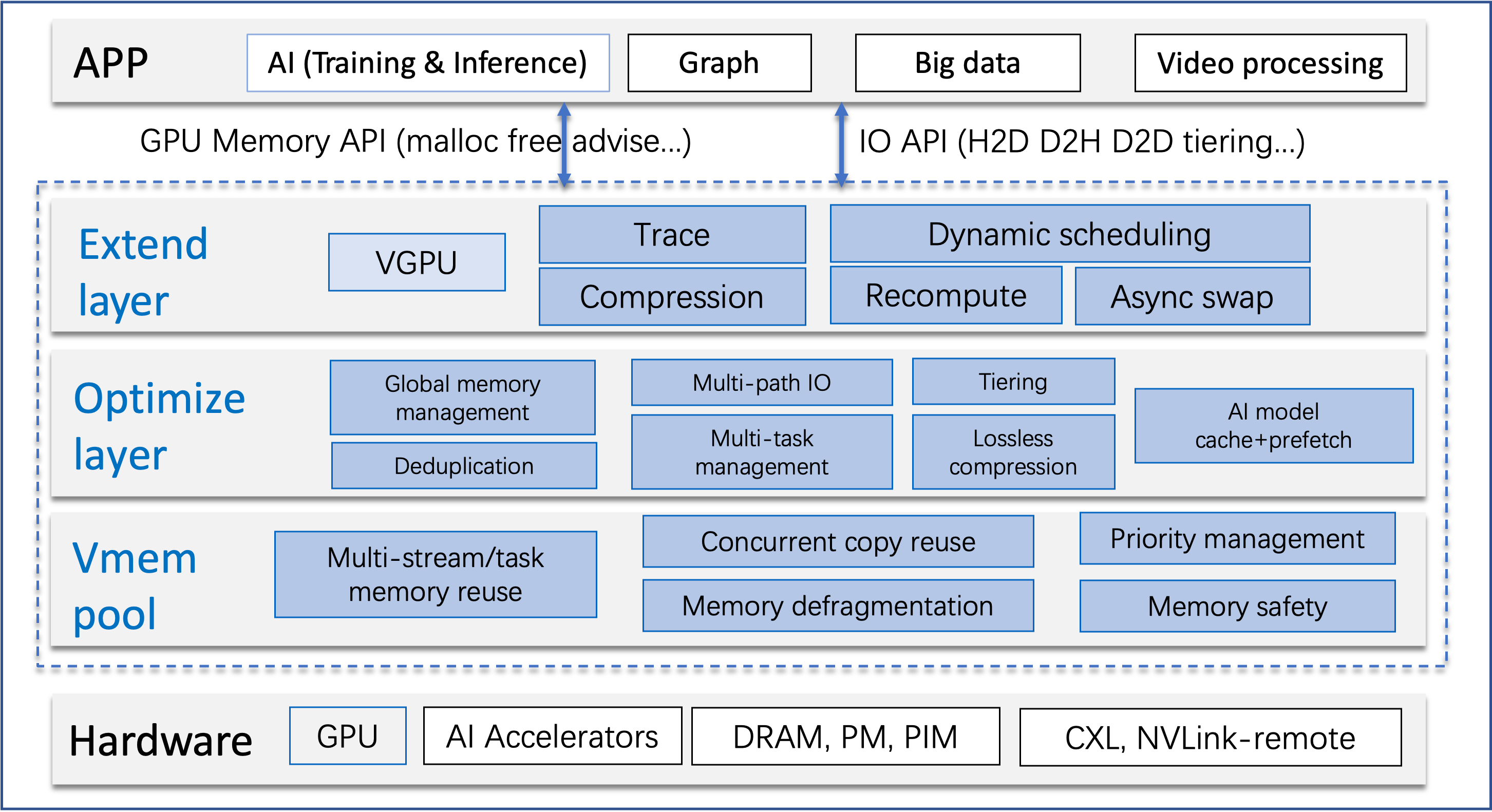
Large-scale deep neural networks (DNNs), such as large language models (LLMs), have revolutionized the artificial intelligence (AI) field and become increasingly popular. However, training or fine-tuning such models requires substantial computational power and resources, where the memory capacity of a single acceleration device like a GPU is one of the most important bottlenecks. Owing to the prohibitively large overhead (e.g., $10 \times$) of GPUs' native memory allocator, DNN frameworks like PyTorch and TensorFlow adopt a caching allocator that maintains a memory pool with a splitting mechanism for fast memory (de)allocation. Unfortunately, the caching allocator's efficiency degrades quickly for popular memory reduction techniques such as recomputation, offloading, distributed training, and low-rank adaptation. The primary reason is that those memory reduction techniques introduce frequent and irregular memory (de)allocation requests, leading to severe fragmentation problems for the splitting-based caching allocator. To mitigate this fragmentation problem, we propose a novel memory allocation framework based on low-level GPU virtual memory management called GPU memory lake (GMLake). GMLake employs a novel virtual memory stitching (VMS) mechanism, which can fuse or combine non-contiguous memory blocks with a virtual memory address mapping. GMLake can reduce an average of 9.2 GB (up to 25 GB) GPU memory usage and 15% (up to 33% ) fragmentation among eight LLM models on GPU A100 with 80 GB memory. GMLake is completely transparent to the DNN models and memory reduction techniques and ensures the seamless execution of resource-intensive deep-learning tasks. We have open-sourced GMLake at https://github.com/intelligent-machine-learning/glake/tree/main/GMLake.
PDF Abstract
