Form-NLU: Dataset for the Form Natural Language Understanding
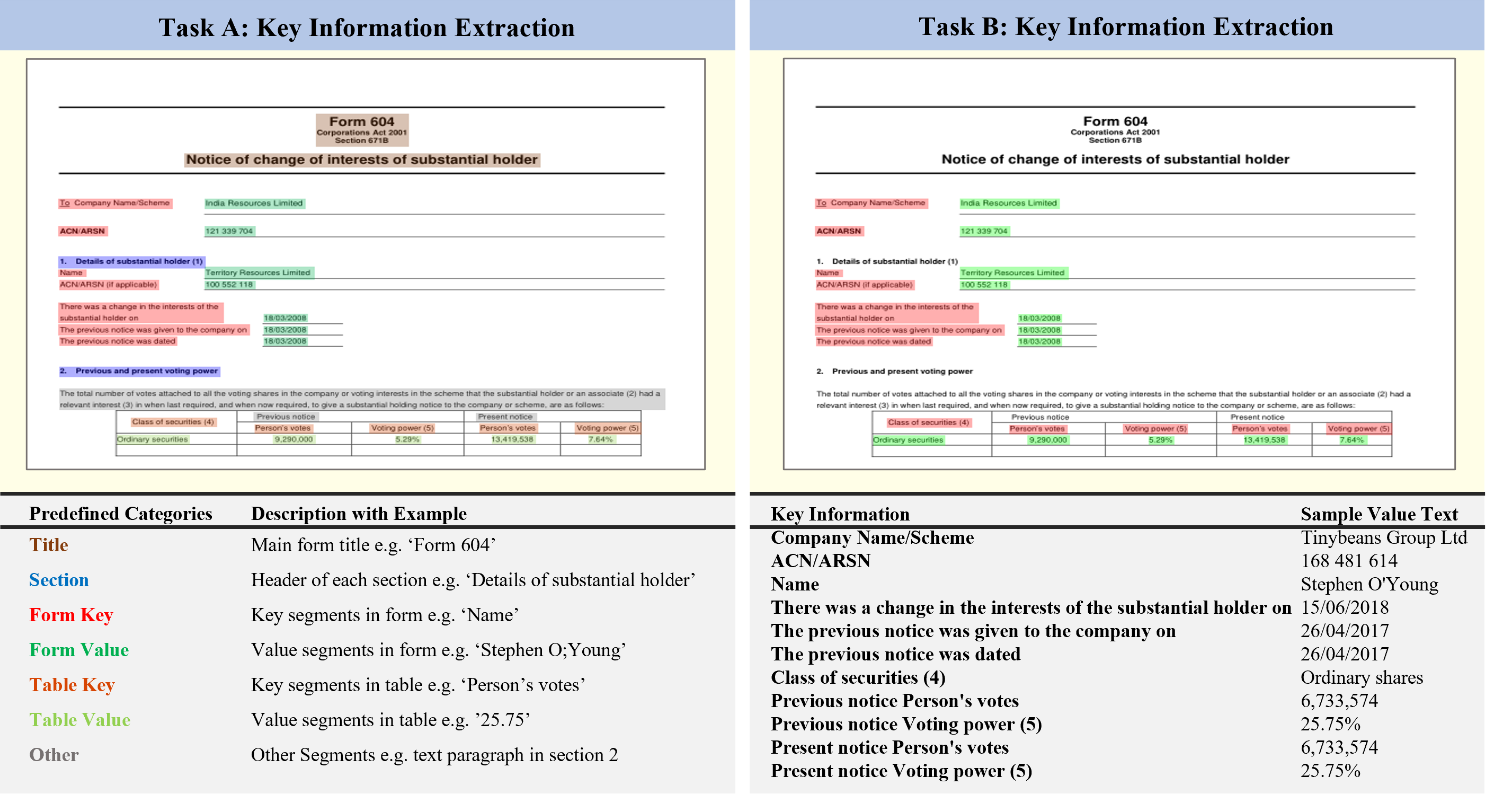
Compared to general document analysis tasks, form document structure understanding and retrieval are challenging. Form documents are typically made by two types of authors; A form designer, who develops the form structure and keys, and a form user, who fills out form values based on the provided keys. Hence, the form values may not be aligned with the form designer's intention (structure and keys) if a form user gets confused. In this paper, we introduce Form-NLU, the first novel dataset for form structure understanding and its key and value information extraction, interpreting the form designer's intent and the alignment of user-written value on it. It consists of 857 form images, 6k form keys and values, and 4k table keys and values. Our dataset also includes three form types: digital, printed, and handwritten, which cover diverse form appearances and layouts. We propose a robust positional and logical relation-based form key-value information extraction framework. Using this dataset, Form-NLU, we first examine strong object detection models for the form layout understanding, then evaluate the key information extraction task on the dataset, providing fine-grained results for different types of forms and keys. Furthermore, we examine it with the off-the-shelf pdf layout extraction tool and prove its feasibility in real-world cases.
PDF Abstract Colab
Colab


 FormNLU
FormNLU
 FUNSD
FUNSD
