Evaluating Mathematical Reasoning Beyond Accuracy
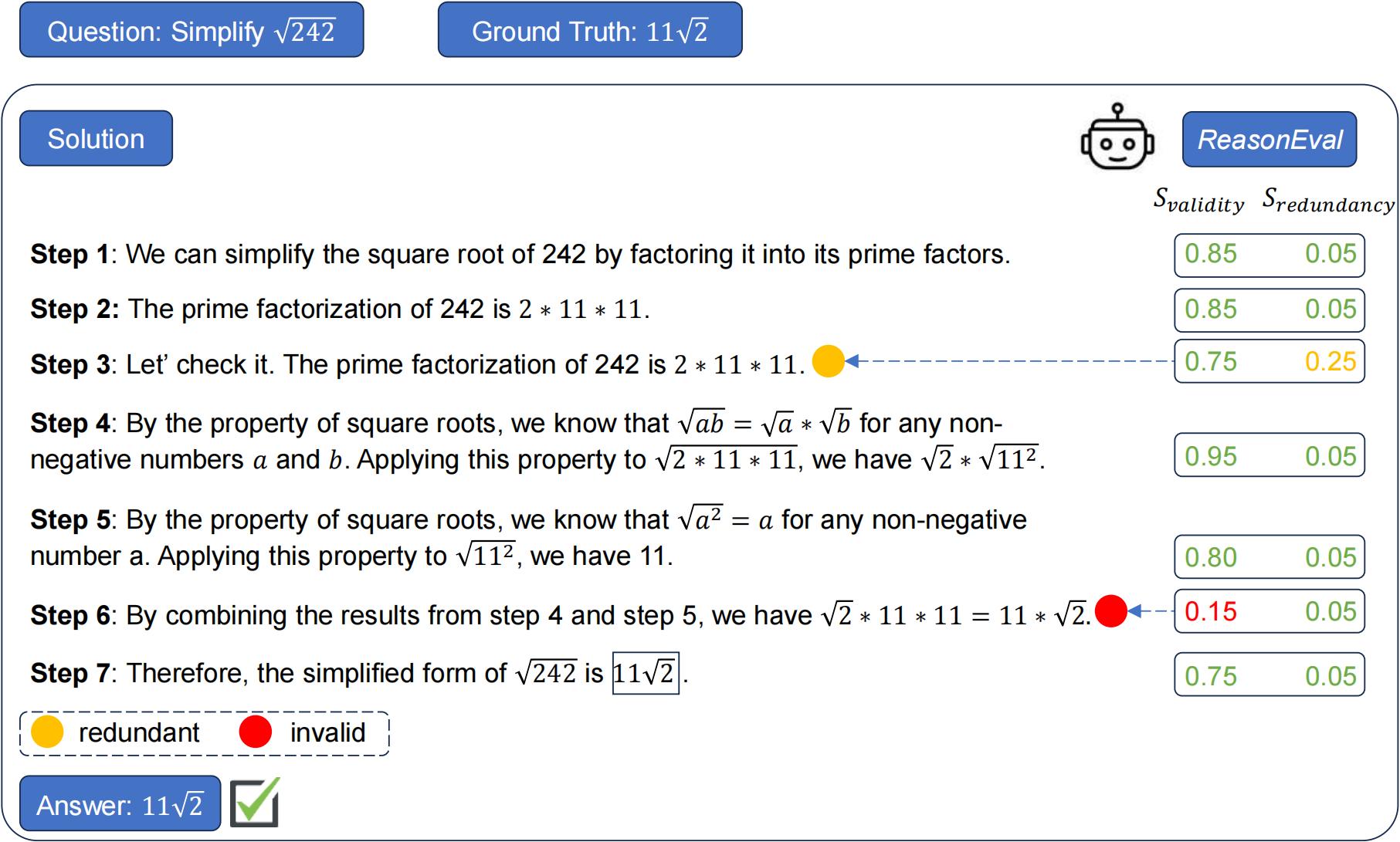
The leaderboard of Large Language Models (LLMs) in mathematical tasks has been continuously updated. However, the majority of evaluations focus solely on the final results, neglecting the quality of the intermediate steps. This oversight can mask underlying problems, such as logical errors or unnecessary steps in the reasoning process. To measure reasoning beyond final-answer accuracy, we introduce ReasonEval, a new methodology for evaluating the quality of reasoning steps. ReasonEval employs $\textit{validity}$ and $\textit{redundancy}$ to characterize the reasoning quality, as well as accompanying LLMs to assess them automatically. Instantiated by base models that possess strong mathematical knowledge and trained with high-quality labeled data, ReasonEval achieves state-of-the-art performance on human-labeled datasets and can accurately detect different types of errors generated by perturbation. When applied to evaluate LLMs specialized in math, we find that an increase in final-answer accuracy does not necessarily guarantee an improvement in the overall quality of the reasoning steps for challenging mathematical problems. Additionally, we observe that ReasonEval can play a significant role in data selection. We release the best-performing model, meta-evaluation script, and all evaluation results at https://github.com/GAIR-NLP/ReasonEval.
PDF Abstract
 Spaces
Spaces

 GSM8K
GSM8K
 MATH
MATH
 PRM800K
PRM800K
