Disentangled Representation Learning for Text-Video Retrieval
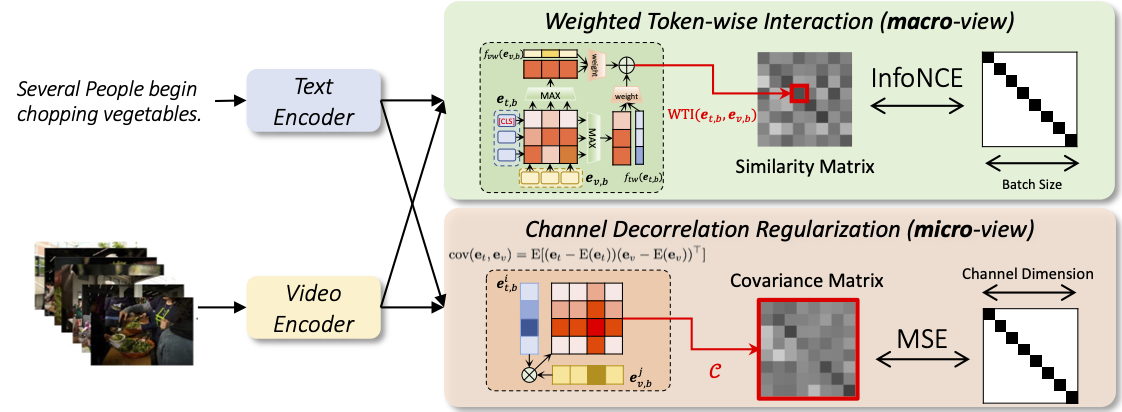
Cross-modality interaction is a critical component in Text-Video Retrieval (TVR), yet there has been little examination of how different influencing factors for computing interaction affect performance. This paper first studies the interaction paradigm in depth, where we find that its computation can be split into two terms, the interaction contents at different granularity and the matching function to distinguish pairs with the same semantics. We also observe that the single-vector representation and implicit intensive function substantially hinder the optimization. Based on these findings, we propose a disentangled framework to capture a sequential and hierarchical representation. Firstly, considering the natural sequential structure in both text and video inputs, a Weighted Token-wise Interaction (WTI) module is performed to decouple the content and adaptively exploit the pair-wise correlations. This interaction can form a better disentangled manifold for sequential inputs. Secondly, we introduce a Channel DeCorrelation Regularization (CDCR) to minimize the redundancy between the components of the compared vectors, which facilitate learning a hierarchical representation. We demonstrate the effectiveness of the disentangled representation on various benchmarks, e.g., surpassing CLIP4Clip largely by +2.9%, +3.1%, +7.9%, +2.3%, +2.8% and +6.5% R@1 on the MSR-VTT, MSVD, VATEX, LSMDC, AcitivityNet, and DiDeMo, respectively.
PDF AbstractCode



 MSR-VTT
MSR-VTT
 DiDeMo
DiDeMo
 LSMDC
LSMDC
 VATEX
VATEX
Results from the Paper
 Ranked #10 on
Video Retrieval
on MSR-VTT-1kA
(using extra training data)
Ranked #10 on
Video Retrieval
on MSR-VTT-1kA
(using extra training data)
