Daft-Exprt: Cross-Speaker Prosody Transfer on Any Text for Expressive Speech Synthesis
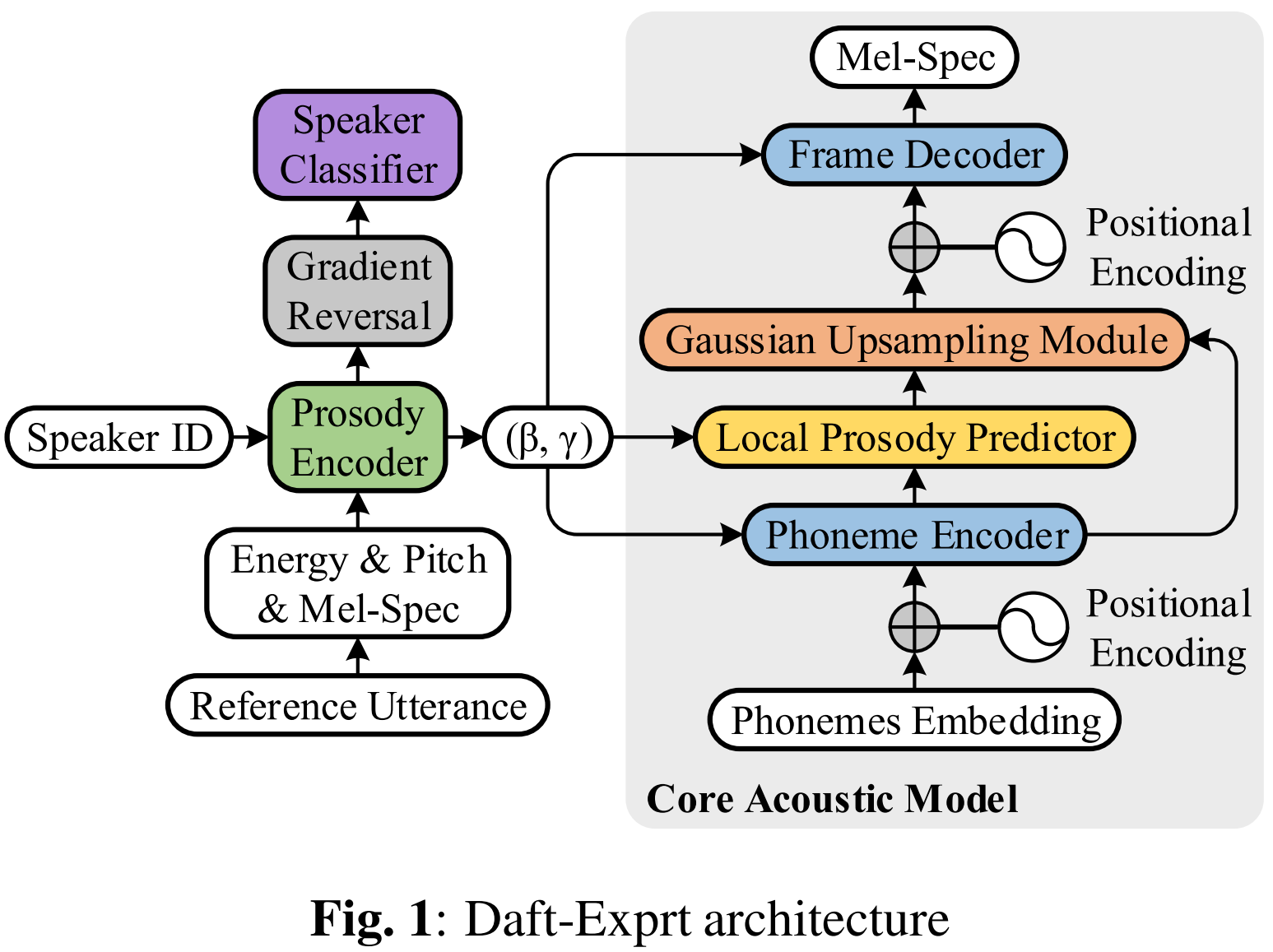
This paper presents Daft-Exprt, a multi-speaker acoustic model advancing the state-of-the-art for cross-speaker prosody transfer on any text. This is one of the most challenging, and rarely directly addressed, task in speech synthesis, especially for highly expressive data. Daft-Exprt uses FiLM conditioning layers to strategically inject different prosodic information in all parts of the architecture. The model explicitly encodes traditional low-level prosody features such as pitch, loudness and duration, but also higher level prosodic information that helps generating convincing voices in highly expressive styles. Speaker identity and prosodic information are disentangled through an adversarial training strategy that enables accurate prosody transfer across speakers. Experimental results show that Daft-Exprt significantly outperforms strong baselines on inter-text cross-speaker prosody transfer tasks, while yielding naturalness comparable to state-of-the-art expressive models. Moreover, results indicate that the model discards speaker identity information from the prosody representation, and consistently generate speech with the desired voice. We publicly release our code and provide speech samples from our experiments.
PDF Abstract
