Convolutional Neural Networks and Language Embeddings for End-to-End Dialect Recognition
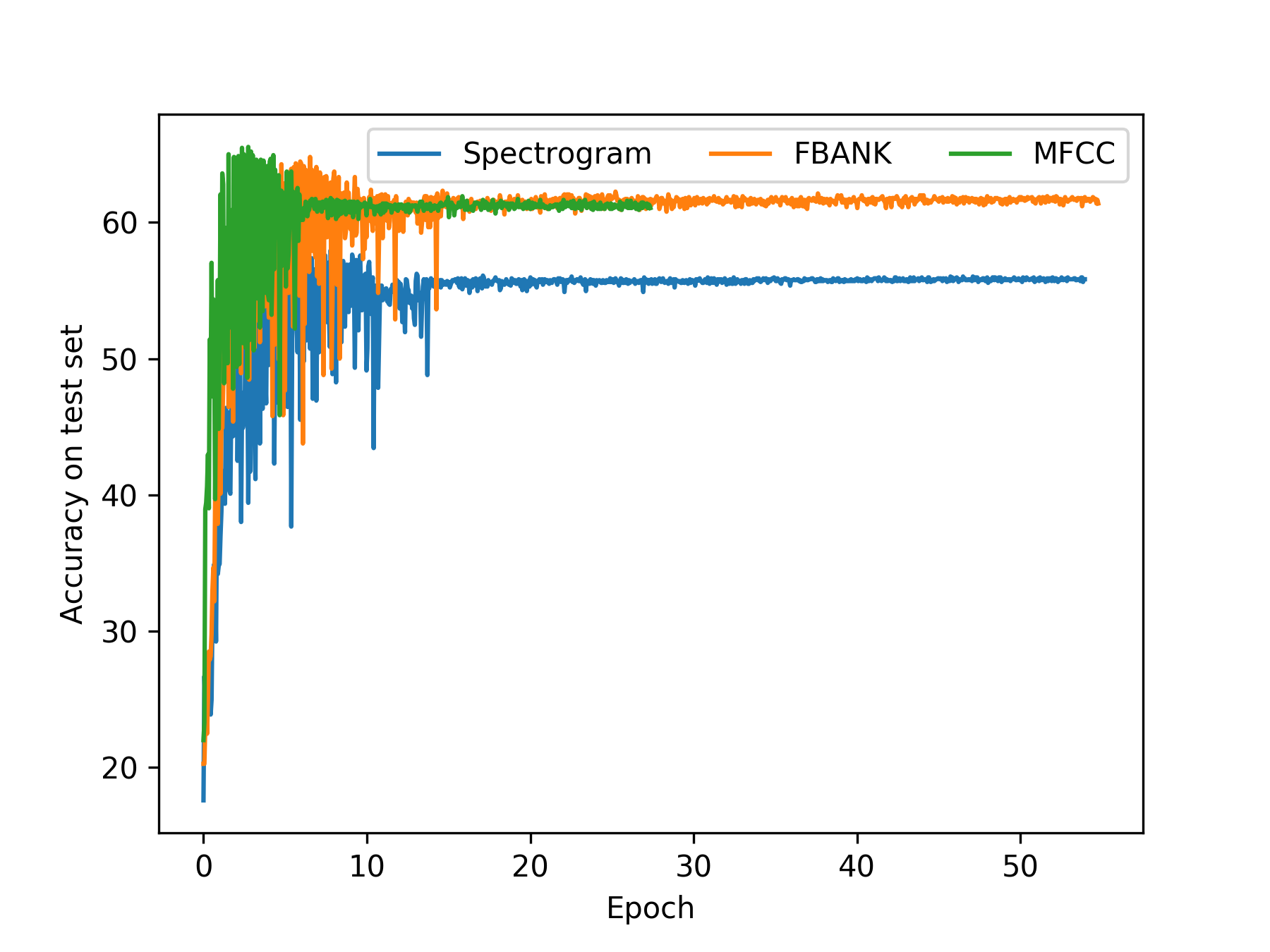
Dialect identification (DID) is a special case of general language identification (LID), but a more challenging problem due to the linguistic similarity between dialects. In this paper, we propose an end-to-end DID system and a Siamese neural network to extract language embeddings. We use both acoustic and linguistic features for the DID task on the Arabic dialectal speech dataset: Multi-Genre Broadcast 3 (MGB-3). The end-to-end DID system was trained using three kinds of acoustic features: Mel-Frequency Cepstral Coefficients (MFCCs), log Mel-scale Filter Bank energies (FBANK) and spectrogram energies. We also investigated a dataset augmentation approach to achieve robust performance with limited data resources. Our linguistic feature research focused on learning similarities and dissimilarities between dialects using the Siamese network, so that we can reduce feature dimensionality as well as improve DID performance. The best system using a single feature set achieves 73% accuracy, while a fusion system using multiple features yields 78% on the MGB-3 dialect test set consisting of 5 dialects. The experimental results indicate that FBANK features achieve slightly better results than MFCCs. Dataset augmentation via speed perturbation appears to add significant robustness to the system. Although the Siamese network with language embeddings did not achieve as good a result as the end-to-end DID system, the two approaches had good synergy when combined together in a fused system.
PDF Abstract
