CED: Consistent ensemble distillation for audio tagging
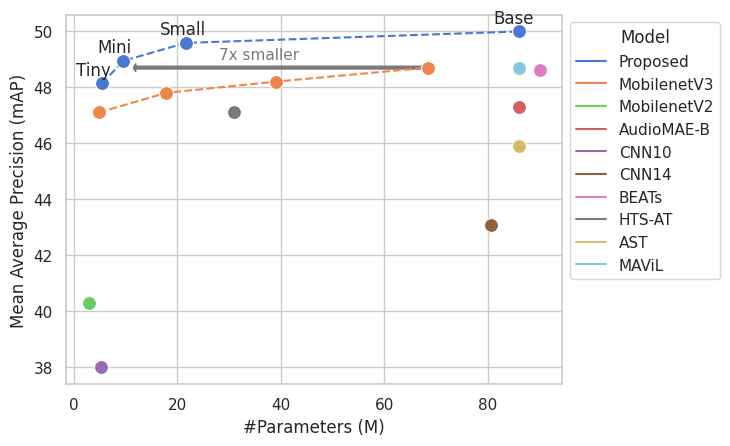
Augmentation and knowledge distillation (KD) are well-established techniques employed in audio classification tasks, aimed at enhancing performance and reducing model sizes on the widely recognized Audioset (AS) benchmark. Although both techniques are effective individually, their combined use, called consistent teaching, hasn't been explored before. This paper proposes CED, a simple training framework that distils student models from large teacher ensembles with consistent teaching. To achieve this, CED efficiently stores logits as well as the augmentation methods on disk, making it scalable to large-scale datasets. Central to CED's efficacy is its label-free nature, meaning that only the stored logits are used for the optimization of a student model only requiring 0.3\% additional disk space for AS. The study trains various transformer-based models, including a 10M parameter model achieving a 49.0 mean average precision (mAP) on AS. Pretrained models and code are available at https://github.com/RicherMans/CED.
PDF Abstract Spaces
Spaces

 AudioSet
AudioSet
