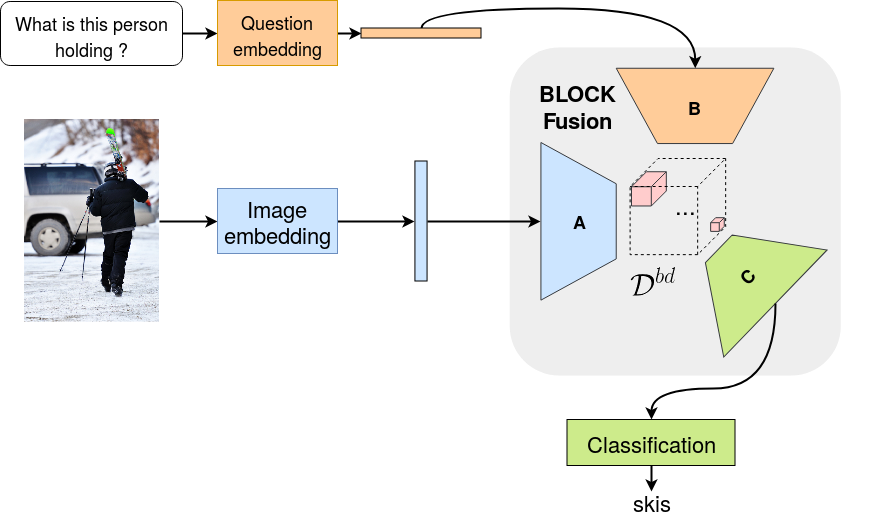
BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection
Multimodal representation learning is gaining more and more interest within the deep learning community. While bilinear models provide an interesting framework to find subtle combination of modalities, their number of parameters grows quadratically with the input dimensions, making their practical implementation within classical deep learning pipelines challenging. In this paper, we introduce BLOCK, a new multimodal fusion based on the block-superdiagonal tensor decomposition. It leverages the notion of block-term ranks, which generalizes both concepts of rank and mode ranks for tensors, already used for multimodal fusion. It allows to define new ways for optimizing the tradeoff between the expressiveness and complexity of the fusion model, and is able to represent very fine interactions between modalities while maintaining powerful mono-modal representations. We demonstrate the practical interest of our fusion model by using BLOCK for two challenging tasks: Visual Question Answering (VQA) and Visual Relationship Detection (VRD), where we design end-to-end learnable architectures for representing relevant interactions between modalities. Through extensive experiments, we show that BLOCK compares favorably with respect to state-of-the-art multimodal fusion models for both VQA and VRD tasks. Our code is available at https://github.com/Cadene/block.bootstrap.pytorch.
PDF Abstract




 Visual Question Answering
Visual Question Answering
 Visual Question Answering v2.0
Visual Question Answering v2.0
 VRD
VRD
 TDIUC
TDIUC

