Attention on Attention: Architectures for Visual Question Answering (VQA)
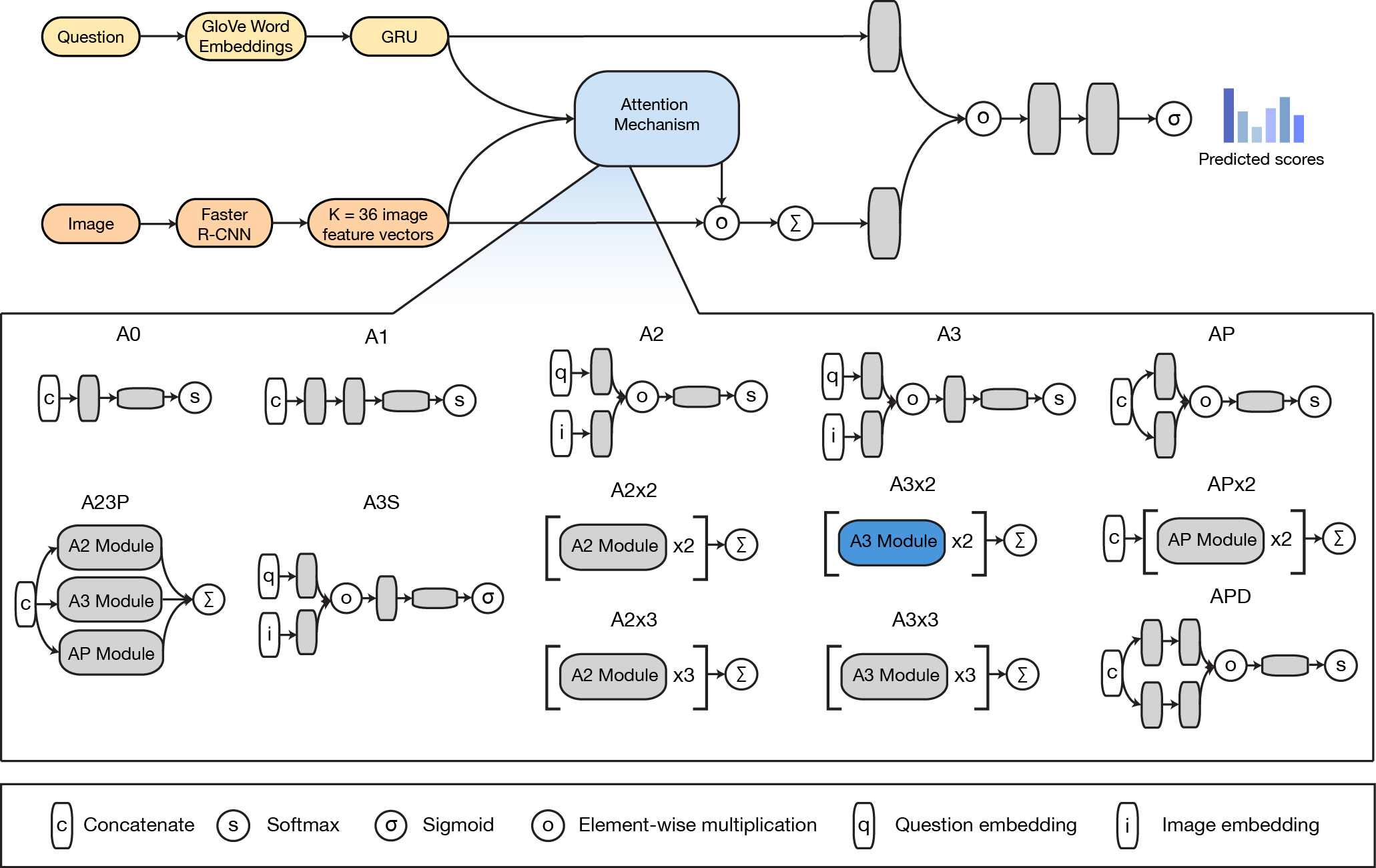
Visual Question Answering (VQA) is an increasingly popular topic in deep learning research, requiring coordination of natural language processing and computer vision modules into a single architecture. We build upon the model which placed first in the VQA Challenge by developing thirteen new attention mechanisms and introducing a simplified classifier. We performed 300 GPU hours of extensive hyperparameter and architecture searches and were able to achieve an evaluation score of 64.78%, outperforming the existing state-of-the-art single model's validation score of 63.15%.
PDF AbstractCode




Datasets
 Visual Question Answering
Visual Question Answering
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
