Asynchronous Execution of the Fast Multipole Method Using Charm++
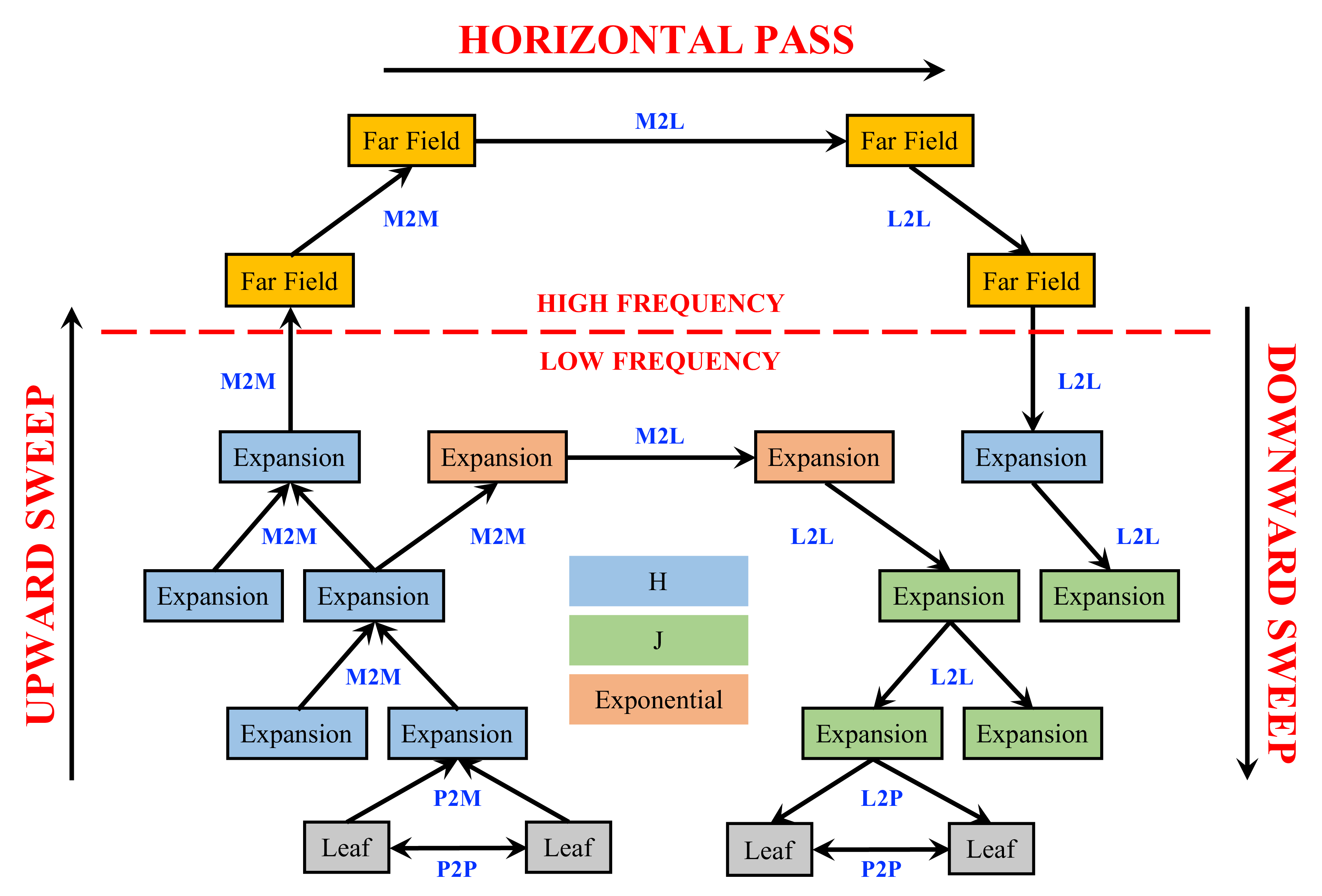
Fast multipole methods (FMM) on distributed mem- ory have traditionally used a bulk-synchronous model of com- municating the local essential tree (LET) and overlapping it with computation of the local data. This could be perceived as an extreme case of data aggregation, where the whole LET is communicated at once. Charm++ allows a much finer control over the granularity of communication, and has a asynchronous execution model that fits well with the structure of our FMM code. Unlike previous work on asynchronous fast N-body methods such as ChaNGa and PEPC, the present work performs a direct comparison against the traditional bulk-synchronous approach and the asynchronous approach using Charm++. Furthermore, the serial performance of our FMM code is over an order of magnitude better than these previous codes, so it is much more challenging to hide the overhead of Charm++.
PDF Abstract