An Approach to Multiple Comparison Benchmark Evaluations that is Stable Under Manipulation of the Comparate Set
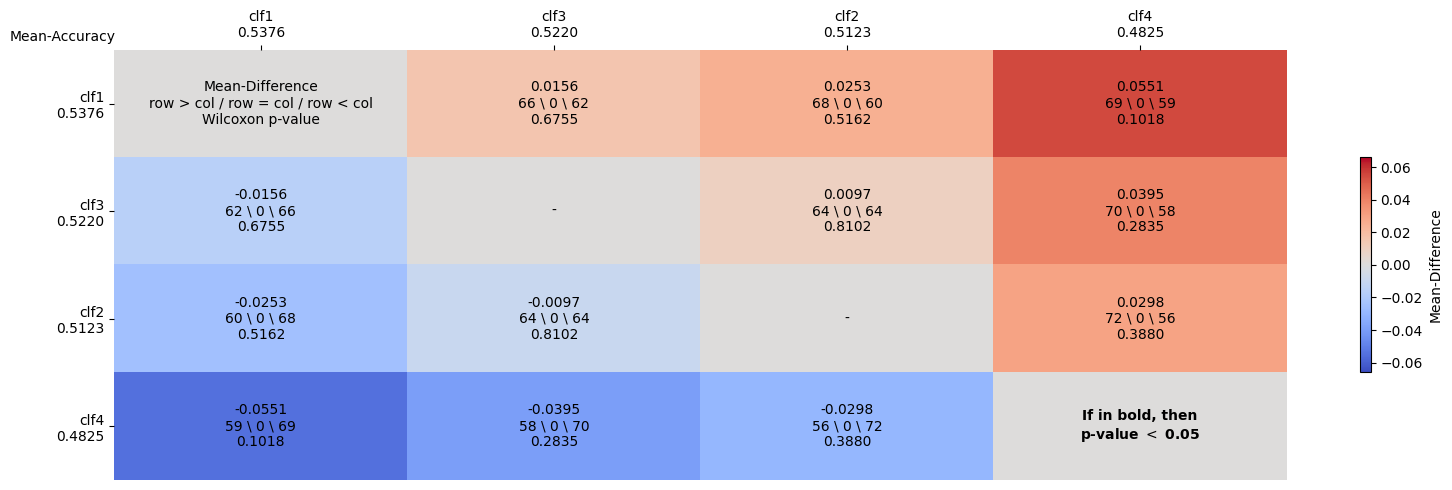
The measurement of progress using benchmarks evaluations is ubiquitous in computer science and machine learning. However, common approaches to analyzing and presenting the results of benchmark comparisons of multiple algorithms over multiple datasets, such as the critical difference diagram introduced by Dem\v{s}ar (2006), have important shortcomings and, we show, are open to both inadvertent and intentional manipulation. To address these issues, we propose a new approach to presenting the results of benchmark comparisons, the Multiple Comparison Matrix (MCM), that prioritizes pairwise comparisons and precludes the means of manipulating experimental results in existing approaches. MCM can be used to show the results of an all-pairs comparison, or to show the results of a comparison between one or more selected algorithms and the state of the art. MCM is implemented in Python and is publicly available.
PDF Abstract
