ProLLaMA: A Protein Large Language Model for Multi-Task Protein Language Processing
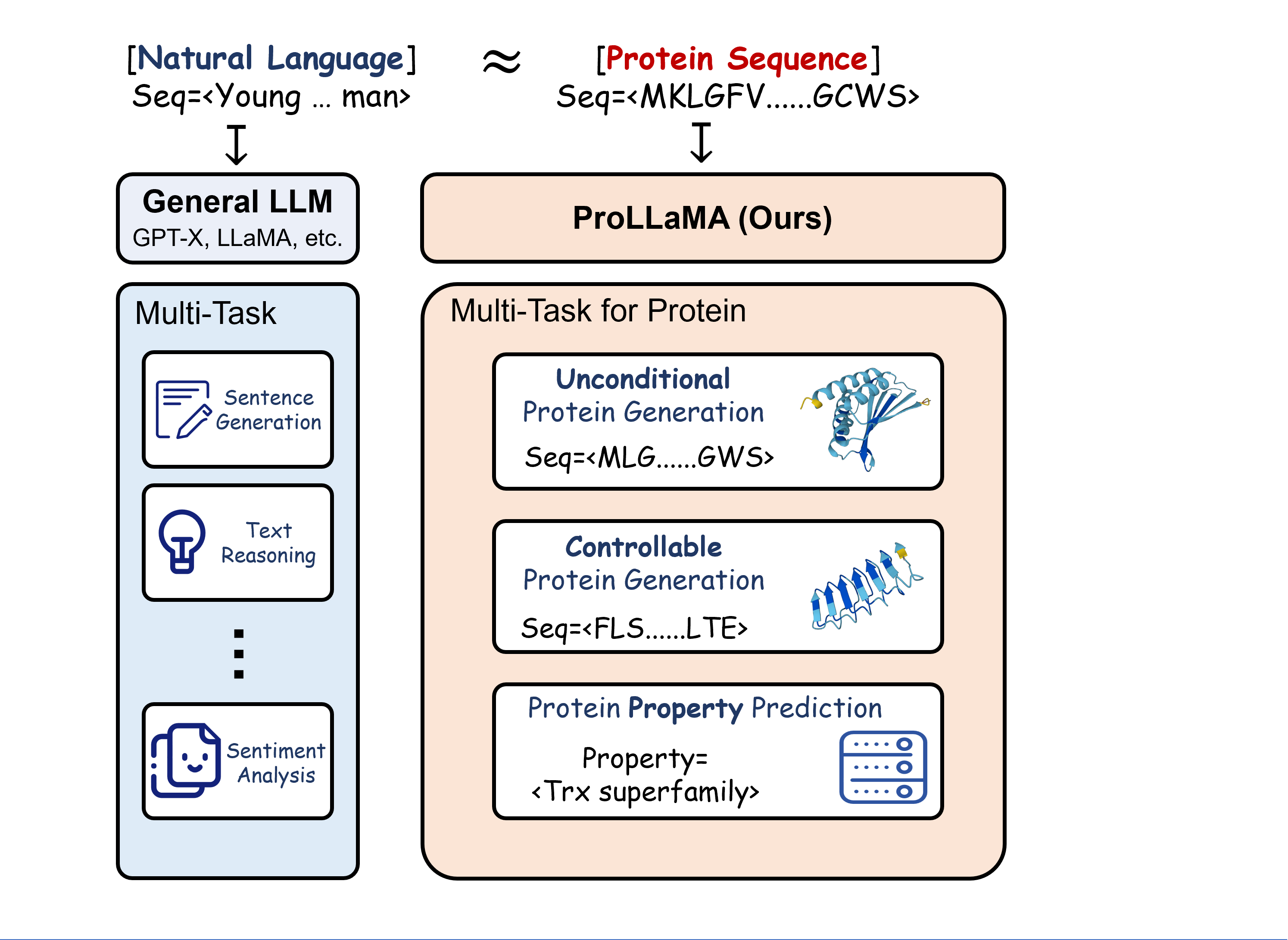
Large Language Models (LLMs), including GPT-x and LLaMA2, have achieved remarkable performance in multiple Natural Language Processing (NLP) tasks. Under the premise that protein sequences constitute the protein language, Protein Large Language Models (ProLLMs) trained on protein corpora excel at de novo protein sequence generation. However, as of now, unlike LLMs in NLP, no ProLLM is capable of multiple tasks in the Protein Language Processing (PLP) field. This prompts us to delineate the inherent limitations in current ProLLMs: (i) the lack of natural language capabilities, (ii) insufficient instruction understanding, and (iii) high training resource demands. To address these challenges, we introduce a training framework to transform any general LLM into a ProLLM capable of handling multiple PLP tasks. Specifically, our framework utilizes low-rank adaptation and employs a two-stage training approach, and it is distinguished by its universality, low overhead, and scalability. Through training under this framework, we propose the ProLLaMA model, the first known ProLLM to handle multiple PLP tasks simultaneously. Experiments show that ProLLaMA achieves state-of-the-art results in the unconditional protein sequence generation task. In the controllable protein sequence generation task, ProLLaMA can design novel proteins with desired functionalities. In the protein property prediction task, ProLLaMA achieves nearly 100\% accuracy across many categories. The latter two tasks are beyond the reach of other ProLLMs. Code is available at \url{https://github.com/Lyu6PosHao/ProLLaMA}.
PDF Abstract
