 Attention Mechanisms
Attention Mechanisms
Dual Multimodal Attention
Introduced by Zhang et al. in Text-Guided Neural Image InpaintingIn image inpainting task, the mechanism extracts complementary features from the word embedding in two paths by reciprocal attention, which is done by comparing the descriptive text and complementary image areas through reciprocal attention.
Source: Text-Guided Neural Image Inpainting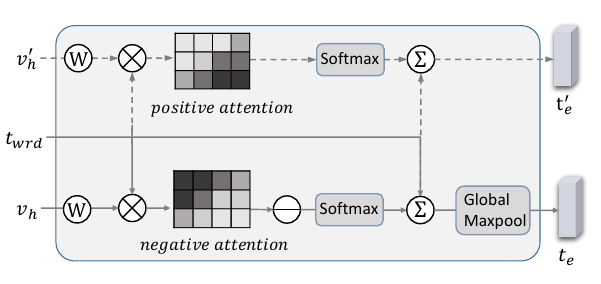
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Fairness | 2 | 11.11% |
| Object Detection | 2 | 11.11% |
| Semantic Segmentation | 2 | 11.11% |
| 3D Object Detection | 1 | 5.56% |
| Scene Understanding | 1 | 5.56% |
| Image Segmentation | 1 | 5.56% |
| Data Poisoning | 1 | 5.56% |
| Federated Learning | 1 | 5.56% |
| Jurisprudence | 1 | 5.56% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
