Crowd 11 (A Dataset for Fine Grained Crowd Behaviour Analysis)
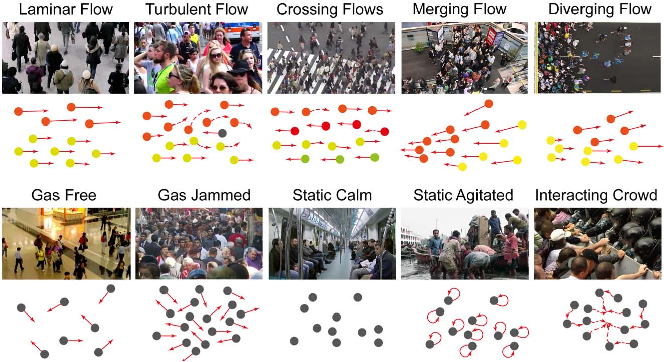
This dataset defines a total of 11 crowd motion patterns and it is composed of over 6000 video sequences with an average length of 100 frames per sequence. This documentation presents how to download and process the Crowd-11 dataset.
If you use this dataset, please cite our paper:
Camille Dupont, Luis Tobias, and Bertrand Luvison. "Crowd-11: A Dataset for Fine Grained Crowd Behaviour Analysis." In Computer Vision and Pattern Recognition Workshops (CVPRW), 2017.
Since this dataset is a composition of web videos and already existing datasets, we ask you to download and accept licence of each source and dataset. The construction of the Crowd-11 dataset is composed of two steps:
Step 1: Retrieve videos of interest from the web and/or pre-existing datasets
Retrieve the pre-existing datasets of interest
The pre-existing datasets are:
| DATASET NAME | url | $SOURCE_NAME |
|---|---|---|
| UMN | http://mha.cs.umn.edu/proj_events.shtml#crowd | umn |
| AGORASET | https://www.sites.univ-rennes2.fr/costel/corpetti/agoraset/Site/AGORASET.html | agoraset |
| PETS | http://www.cvg.reading.ac.uk/PETS2009/a.html#s3 | pets |
| HOCKEY FIGHT | http://visilab.etsii.uclm.es/personas/oscar/FightDetection/ | hockey |
| MOVIES | http://visilab.etsii.uclm.es/personas/oscar/FightDetection/ | peliculas |
| CUHK | http://www.ee.cuhk.edu.hk/~jshao/CUHKcrowd_files/cuhk_crowd_dataset.htm | cuhk |
| WWW | http://www.ee.cuhk.edu.hk/~jshao/WWWCrowdDataset.html | www |
| WORLDEXPO'10 CROWD COUNTING | http://www.ee.cuhk.edu.hk/~xgwang/expo.html | shanghai |
| VIOLENT-FLOWS | http://www.openu.ac.il/home/hassner/data/violentflows/ | violent_flow |
These datasets should be stored in their "existing_datasets/$SOURCE_NAME/" folder:
.
└── existing_datasets
├── agoraset
├── cuhk
├── hockey
├── peliculas
│ ├── fights
│ └── noFights
├── pets
├── shanghai
├── umn
├── violent_flow
└── www
Copy the videos of interest from the datasets of interest
The list of the videos of interest is in existing_datasets_urls.csv. To extract them into the VOI folder, execute:
python existing_datasets_gathering.py
The VOI folder should have the following structure:
.
└── VOI
├── agoraset
├── cuhk
├── hockey
├── peliculas
├── pets
├── shanghai
├── umn
├── violent_flow
└── www
Download the videos of interest from the web
The web sources are:
| SOURCE NAME | url | $SOURCE_NAME |
|---|---|---|
| YOUTUBE | https://www.youtube.com/ | youtube |
| GETTYIMAGES | http://www.gettyimages.fr/ | gettyimages |
| POND5 | https://www.pond5.com/ | pond5 |
The list of the web urls to download is in web_urls.csv. The web_urls.csv file's structure is as follows :
| $SOURCE NAME | URL | OUTPUT_NAME | TS_MULTIPLIER |
|---|---|---|---|
We do not provide the script to download them, but many tools exist to do it (pytube, urllib, etc...). Note: a few videos have a ts_multiplier field. These video are in slow motion and the ts_multiplier is provided to speed them up (cf. SETPTS option in avconv).
The downloaded videos should be stored in their VOI/$SOURCE_NAME folder, which should now have the following structure:
.
└── VOI
├── agoraset
├── cuhk
├── gettyimages
├── hockey
├── peliculas
├── pets
├── pond5
├── shanghai
├── umn
├── violent_flow
├── youtube
└── www
Step 2: Processing original videos into the Crowd-11 dataset
Once the VOI folder is complete, a preprocessing step is required in order to crop and trim the original videos into the Crowd-11 dataset.
The preprocessing.csv file's structure is as follows :
| Videoname | Label | Frame_start | Frame_end | Top_left | Top_right | Width | Height | $SOURCE_NAME | Scene_number | Crop_number |
|---|---|---|---|---|---|---|---|---|---|---|
Installation:
You need to have avconv installed:
sudo apt-get install avconv
Then, you need to install several python package. A virtualeenv installation is recommended:
virtualenv -p python3 py
source py/bin/activate
pip install sk-video
Execution (in the virtualenv):
python script_formating.py
Papers
| Paper | Code | Results | Date | Stars |
|---|

