Search Results for author:
Found 196 papers, 89 papers with code
Implicit Relation Linking for Question Answering over Knowledge Graph
In this paper, we propose an implicit RL method called ImRL, which links relation phrases in NL to relation paths in KG.

ForumSum: A Multi-Speaker Conversation Summarization Dataset
We also show that using a conversational corpus for pre-training improves the quality of the chat summarization model.
SGFormer: Spherical Geometry Transformer for 360 Depth Estimation
Panoramic distortion poses a significant challenge in 360 depth estimation, particularly pronounced at the north and south poles.

Digging into contrastive learning for robust depth estimation with diffusion models
In this paper, we propose a novel robust depth estimation method called D4RD, featuring a custom contrastive learning mode tailored for diffusion models to mitigate performance degradation in complex environments.


Transferable and Principled Efficiency for Open-Vocabulary Segmentation
In the context of efficient OVS, we target achieving performance that is comparable to or even better than prior OVS works based on large vision-language foundation models, by utilizing smaller models that incur lower training costs.
TransformerLSR: Attentive Joint Model of Longitudinal Data, Survival, and Recurrent Events with Concurrent Latent Structure
However, current methods only address joint modeling of longitudinal measurements at regularly-spaced observation times and survival events, neglecting recurrent events.
Learning Trimaps via Clicks for Image Matting
Despite significant advancements in image matting, existing models heavily depend on manually-drawn trimaps for accurate results in natural image scenarios.

BlindDiff: Empowering Degradation Modelling in Diffusion Models for Blind Image Super-Resolution
BlindDiff seamlessly integrates the MAP-based optimization into DMs, which constructs a joint distribution of the low-resolution (LR) observation, high-resolution (HR) data, and degradation kernels for the data and kernel priors, and solves the blind SR problem by unfolding MAP approach along with the reverse process.

Learning Hierarchical Color Guidance for Depth Map Super-Resolution
On the one hand, the low-level detail embedding module is designed to supplement high-frequency color information of depth features in a residual mask manner at the low-level stages.

Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Learning
Consequently, these detectors have exhibited a lack of proficiency in learning the frequency domain and tend to overfit to the artifacts present in the training data, leading to suboptimal performance on unseen sources.


Towards the Uncharted: Density-Descending Feature Perturbation for Semi-supervised Semantic Segmentation
Inspired by the low-density separation assumption in semi-supervised learning, our key insight is that feature density can shed a light on the most promising direction for the segmentation classifier to explore, which is the regions with lower density.

SiGNN: A Spike-induced Graph Neural Network for Dynamic Graph Representation Learning
In the domain of dynamic graph representation learning (DGRL), the efficient and comprehensive capture of temporal evolution within real-world networks is crucial.

Eliminating Warping Shakes for Unsupervised Online Video Stitching
In this paper, we retarget video stitching to an emerging issue, named warping shake, when extending image stitching to video stitching.

Query-guided Prototype Evolution Network for Few-Shot Segmentation
To address this, we present the Query-guided Prototype Evolution Network (QPENet), a new method that integrates query features into the generation process of foreground and background prototypes, thereby yielding customized prototypes attuned to specific queries.
Data-Independent Operator: A Training-Free Artifact Representation Extractor for Generalizable Deepfake Detection
Due to its unbias towards both the training and test sources, we define it as Data-Independent Operator (DIO) to achieve appealing improvements on unseen sources.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
In this report, we present the latest model of the Gemini family, Gemini 1. 5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio.
 Ranked #20 on
Code Generation
on HumanEval
Ranked #20 on
Code Generation
on HumanEval


Region-Adaptive Transform with Segmentation Prior for Image Compression
However, there is no prior research on neural transform that focuses on specific regions.
 Ranked #1 on
Image Compression
on kodak
Ranked #1 on
Image Compression
on kodak
Direct Language Model Alignment from Online AI Feedback
Moreover, responses in these datasets are often sampled from a language model distinct from the one being aligned, and since the model evolves over training, the alignment phase is inevitably off-policy.

LiPO: Listwise Preference Optimization through Learning-to-Rank
In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt.
EASRec: Elastic Architecture Search for Efficient Long-term Sequential Recommender Systems
Our research addresses the computational and resource inefficiencies that current Sequential Recommender Systems (SRSs) suffer from.


One for all: A novel Dual-space Co-training baseline for Large-scale Multi-View Clustering
We jointly optimize the construction of the latent consistent anchor graph and the feature transformation to generate a discriminative anchor graph.

Semi-Supervised Coupled Thin-Plate Spline Model for Rotation Correction and Beyond
To break this bottleneck, we propose the coupled thin-plate spline model (CoupledTPS), which iteratively couples multiple TPS with limited control points into a more flexible and powerful transformation.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
The rapid development of open-source large language models (LLMs) has been truly remarkable.
4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency
Our pipeline facilitates conditional 4D generation, enabling users to specify geometry (3D assets) and motion (monocular videos), thus offering superior control over content creation.

Forgery-aware Adaptive Transformer for Generalizable Synthetic Image Detection
In this paper, we study the problem of generalizable synthetic image detection, aiming to detect forgery images from diverse generative methods, e. g., GANs and diffusion models.
360 Layout Estimation via Orthogonal Planes Disentanglement and Multi-view Geometric Consistency Perception
Existing panoramic layout estimation solutions tend to recover room boundaries from a vertically compressed sequence, yielding imprecise results as the compression process often muddles the semantics between various planes.
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy
Hence, this paper presents a generic framework for accelerating the inference process, resulting in a substantial increase in speed and cost reduction for our RAG system, with lossless generation accuracy.
Gemini: A Family of Highly Capable Multimodal Models
This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding.
 Ranked #1 on
Multi-task Language Understanding
on MMLU
Ranked #1 on
Multi-task Language Understanding
on MMLU
SegRefiner: Towards Model-Agnostic Segmentation Refinement with Discrete Diffusion Process
We propose a model-agnostic solution called SegRefiner, which offers a novel perspective on this problem by interpreting segmentation refinement as a data generation process.

Rethinking the Up-Sampling Operations in CNN-based Generative Network for Generalizable Deepfake Detection
Recently, the proliferation of highly realistic synthetic images, facilitated through a variety of GANs and Diffusions, has significantly heightened the susceptibility to misuse.
Multiple Instance Learning for Uplift Modeling
Uplift modeling is widely used in performance marketing to estimate effects of promotion campaigns (e. g., increase of customer retention rate).
Self-Evaluation Improves Selective Generation in Large Language Models
Safe deployment of large language models (LLMs) may benefit from a reliable method for assessing their generated content to determine when to abstain or to selectively generate.
Semantic Lens: Instance-Centric Semantic Alignment for Video Super-Resolution
As a critical clue of video super-resolution (VSR), inter-frame alignment significantly impacts overall performance.

Diffusion for Natural Image Matting
However, the presence of high computational overhead and the inconsistency of noise sampling between the training and inference processes pose significant obstacles to achieving this goal.
 Ranked #1 on
Image Matting
on Distinctions-646
Ranked #1 on
Image Matting
on Distinctions-646
Large Multimodal Model Compression via Efficient Pruning and Distillation at AntGroup
In our research, we constructed a dataset, the Multimodal Advertisement Audition Dataset (MAAD), from real-world scenarios within Alipay, and conducted experiments to validate the reliability of our proposed strategy.
PixelLM: Pixel Reasoning with Large Multimodal Model
PixelLM excels across various pixel-level image reasoning and understanding tasks, outperforming well-established methods in multiple benchmarks, including MUSE, single- and multi-referring segmentation.
On What Basis? Predicting Text Preference Via Structured Comparative Reasoning
Comparative reasoning plays a crucial role in text preference prediction; however, large language models (LLMs) often demonstrate inconsistencies in their reasoning.
On the Opportunities of Green Computing: A Survey
To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic.

Unleashing the potential of GNNs via Bi-directional Knowledge Transfer
On this basis, BiKT not only allows us to acquire knowledge from both the GNN and its derived model but promotes each other by injecting the knowledge into the other.


WeatherDepth: Curriculum Contrastive Learning for Self-Supervised Depth Estimation under Adverse Weather Conditions
In this paper, we propose WeatherDepth, a self-supervised robust depth estimation model with curriculum contrastive learning, to tackle performance degradation in complex weather conditions.
Learning Mask-aware CLIP Representations for Zero-Shot Segmentation
However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image.

 Open Vocabulary Semantic Segmentation
Zero Shot Segmentation
Open Vocabulary Semantic Segmentation
Zero Shot Segmentation
IBVC: Interpolation-driven B-frame Video Compression
Learned B-frame video compression aims to adopt bi-directional motion estimation and motion compensation (MEMC) coding for middle frame reconstruction.
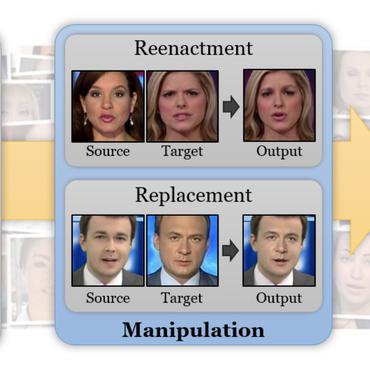
Unified Frequency-Assisted Transformer Framework for Detecting and Grounding Multi-Modal Manipulation
Moreover, to address the semantic conflicts between image and frequency domains, the forgery-aware mutual module is developed to further enable the effective interaction of disparate image and frequency features, resulting in aligned and comprehensive visual forgery representations.
Statistical Rejection Sampling Improves Preference Optimization
DPO's lack of a reward model constrains its ability to sample preference pairs from the optimal policy, and SLiC is restricted to sampling preference pairs only from the SFT policy.
Frequency Perception Network for Camouflaged Object Detection
Camouflaged object detection (COD) aims to accurately detect objects hidden in the surrounding environment.
SDDNet: Style-guided Dual-layer Disentanglement Network for Shadow Detection
Despite significant progress in shadow detection, current methods still struggle with the adverse impact of background color, which may lead to errors when shadows are present on complex backgrounds.

CTP: Towards Vision-Language Continual Pretraining via Compatible Momentum Contrast and Topology Preservation
Regarding the growing nature of real-world data, such an offline training paradigm on ever-expanding data is unsustainable, because models lack the continual learning ability to accumulate knowledge constantly.

Group Pose: A Simple Baseline for End-to-End Multi-person Pose Estimation
State-of-the-art solutions adopt the DETR-like framework, and mainly develop the complex decoder, e. g., regarding pose estimation as keypoint box detection and combining with human detection in ED-Pose, hierarchically predicting with pose decoder and joint (keypoint) decoder in PETR.
CLE Diffusion: Controllable Light Enhancement Diffusion Model
Low light enhancement has gained increasing importance with the rapid development of visual creation and editing.

You Can Mask More For Extremely Low-Bitrate Image Compression
Extensive experiments have demonstrated that our approach outperforms recent state-of-the-art methods in R-D performance, visual quality, and downstream applications, at very low bitrates.
Exploring Resolution Fields for Scalable Image Compression with Uncertainty Guidance
In this work, we explore the potential of resolution fields in scalable image compression and propose the reciprocal pyramid network (RPN) that fulfills the need for more adaptable and versatile compression.
NPVForensics: Jointing Non-critical Phonemes and Visemes for Deepfake Detection
Next, we design a phoneme-viseme awareness module for cross-modal feature fusion and representation alignment, so that the modality gap can be reduced and the intrinsic complementarity of the two modalities can be better explored.
Tensorized Hypergraph Neural Networks
THNN is a faithful hypergraph modeling framework through high-order outer product feature message passing and is a natural tensor extension of the adjacency-matrix-based graph neural networks.
A Hybrid Approach for Smart Alert Generation
Anomaly detection is an important task in network management.

SLiC-HF: Sequence Likelihood Calibration with Human Feedback
Past work has often relied on Reinforcement Learning from Human Feedback (RLHF), which optimizes the language model using reward scores assigned from a reward model trained on human preference data.
Lyapunov-Stable Deep Equilibrium Models
Deep equilibrium (DEQ) models have emerged as a promising class of implicit layer models, which abandon traditional depth by solving for the fixed points of a single nonlinear layer.
Progressive Semantic-Visual Mutual Adaption for Generalized Zero-Shot Learning
Generalized Zero-Shot Learning (GZSL) identifies unseen categories by knowledge transferred from the seen domain, relying on the intrinsic interactions between visual and semantic information.
Deep Learning for Camera Calibration and Beyond: A Survey
In this paper, we provide a comprehensive survey of learning-based camera calibration techniques, by analyzing their strengths and limitations.
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Recent advancements in pre-trained vision-language models, such as CLIP, have enabled the segmentation of arbitrary concepts solely from textual inputs, a process commonly referred to as open-vocabulary semantic segmentation (OVS).
Knowledge Distillation
Open Vocabulary Semantic Segmentation
+4
SigVIC: Spatial Importance Guided Variable-Rate Image Compression
Variable-rate mechanism has improved the flexibility and efficiency of learning-based image compression that trains multiple models for different rate-distortion tradeoffs.
Disentangling Orthogonal Planes for Indoor Panoramic Room Layout Estimation with Cross-Scale Distortion Awareness
Based on the Manhattan World assumption, most existing indoor layout estimation schemes focus on recovering layouts from vertically compressed 1D sequences.
Unsupervised OmniMVS: Efficient Omnidirectional Depth Inference via Establishing Pseudo-Stereo Supervision
In this paper, we propose the first unsupervised omnidirectional MVS framework based on multiple fisheye images.
Parallax-Tolerant Unsupervised Deep Image Stitching
First, we propose a robust and flexible warp to model the image registration from global homography to local thin-plate spline motion.

Spatiotemporal Deformation Perception for Fisheye Video Rectification
Subsequently, we observe that the inter-frame optical flow of the video is facilitated to perceive the local spatial deformation of the fisheye video.

Dual Diffusion Architecture for Fisheye Image Rectification: Synthetic-to-Real Generalization
To this end, we propose a Dual Diffusion Architecture (DDA) for the fisheye rectification with a better generalization ability.
RecRecNet: Rectangling Rectified Wide-Angle Images by Thin-Plate Spline Model and DoF-based Curriculum Learning
In this work, we explore constructing a win-win representation on both content and boundary by contributing a new learning model, i. e., Rectangling Rectification Network (RecRecNet).
Innovating Real Fisheye Image Correction with Dual Diffusion Architecture
Fisheye image rectification is hindered by synthetic models producing poor results for real-world correction.
CTP:Towards Vision-Language Continual Pretraining via Compatible Momentum Contrast and Topology Preservation
Regarding the growing nature of real-world data, such an offline training paradigm on ever-expanding data is unsustainable, because models lack the continual learning ability to accumulate knowledge constantly.
Locating Noise is Halfway Denoising for Semi-Supervised Segmentation
This work shows that locating the patch-wise noisy region is a better way to deal with noise.
Learning To Segment Every Referring Object Point by Point
Extensive experiments show that our model achieves 52. 06% in terms of accuracy (versus 58. 93% in fully supervised setting) on RefCOCO+@testA, when only using 1% of the mask annotations.
Learning on Gradients: Generalized Artifacts Representation for GAN-Generated Images Detection
The key of fake image detection is to develop a generalized representation to describe the artifacts produced by generation models.

An In-Depth Exploration of Person Re-Identification and Gait Recognition in Cloth-Changing Conditions
For the cloth-changing problem, video-based ReID is rarely studied due to the lack of a suitable cloth-changing benchmark, and gait recognition is often researched under controlled conditions.

Multi-Projection Fusion and Refinement Network for Salient Object Detection in 360° Omnidirectional Image
Salient object detection (SOD) aims to determine the most visually attractive objects in an image.
Improving the Robustness of Summarization Models by Detecting and Removing Input Noise
We present a large empirical study quantifying the sometimes severe loss in performance (up to 12 ROUGE-1 points) from different types of input noise for a range of datasets and model sizes.
Fully and Weakly Supervised Referring Expression Segmentation with End-to-End Learning
To validate our framework on a weakly-supervised setting, we annotated three RES benchmark datasets (RefCOCO, RefCOCO+ and RefCOCOg) with click annotations. Our method is simple but surprisingly effective, outperforming all previous state-of-the-art RES methods on fully- and weakly-supervised settings by a large margin.
Node-oriented Spectral Filtering for Graph Neural Networks
Graph neural networks (GNNs) have shown remarkable performance on homophilic graph data while being far less impressive when handling non-homophilic graph data due to the inherent low-pass filtering property of GNNs.

Mask Matching Transformer for Few-Shot Segmentation
Typical methods follow the paradigm to firstly learn prototypical features from support images and then match query features in pixel-level to obtain segmentation results.

Learning Detail-Structure Alternative Optimization for Blind Super-Resolution
Recent blind SR methods suggest to reconstruct SR images relying on blur kernel estimation.
Bridging Component Learning with Degradation Modelling for Blind Image Super-Resolution
In this paper, we analyze the degradation of a high-resolution (HR) image from image intrinsic components according to a degradation-based formulation model.
HGV4Risk: Hierarchical Global View-guided Sequence Representation Learning for Risk Prediction
Moreover, the hierarchical representations at both instance level and channel level can be coordinated by the heterogeneous information aggregation under the guidance of global view.

FF2: A Feature Fusion Two-Stream Framework for Punctuation Restoration
To accomplish punctuation restoration, most existing methods focus on introducing extra information (e. g., part-of-speech) or addressing the class imbalance problem.
Cross-view Graph Contrastive Representation Learning on Partially Aligned Multi-view Data
Multi-view representation learning has developed rapidly over the past decades and has been applied in many fields.
Temporal Consistency Learning of inter-frames for Video Super-Resolution
A spatio-temporal stability module is designed to learn the self-alignment from inter-frames.
Revisiting Simple Regret: Fast Rates for Returning a Good Arm
Simple regret is a natural and parameter-free performance criterion for pure exploration in multi-armed bandits yet is less popular than the probability of missing the best arm or an $\epsilon$-good arm, perhaps due to lack of easy ways to characterize it.

PSNet: Parallel Symmetric Network for Video Salient Object Detection
Finally, we use the Importance Perception Fusion (IPF) module to fuse the features from two parallel branches according to their different importance in different scenarios.
Does Thermal Really Always Matter for RGB-T Salient Object Detection?
In addition, considering the role of thermal modality, we set up different cross-modality interaction mechanisms in the encoding phase and the decoding phase.

CIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement.
Calibrating Sequence likelihood Improves Conditional Language Generation
Conditional language models are predominantly trained with maximum likelihood estimation (MLE), giving probability mass to sparsely observed target sequences.
 Ranked #1 on
Abstractive Text Summarization
on CNN / Daily Mail
Ranked #1 on
Abstractive Text Summarization
on CNN / Daily Mail
abstractive question answering
 Abstractive Text Summarization
+5
Abstractive Text Summarization
+5
Out-of-Distribution Detection and Selective Generation for Conditional Language Models
Furthermore, the space of potential low-quality outputs is larger as arbitrary text can be generated and it is important to know when to trust the generated output.
Abstractive Text Summarization
Out-of-Distribution Detection
+1
Boundary Guided Semantic Learning for Real-time COVID-19 Lung Infection Segmentation System
The coronavirus disease 2019 (COVID-19) continues to have a negative impact on healthcare systems around the world, though the vaccines have been developed and national vaccination coverage rate is steadily increasing.
A Weakly Supervised Learning Framework for Salient Object Detection via Hybrid Labels
In this paper, we focus on a new weakly-supervised SOD task under hybrid labels, where the supervision labels include a large number of coarse labels generated by the traditional unsupervised method and a small number of real labels.
 Ranked #7 on
RGB Salient Object Detection
on PASCAL-S
Ranked #7 on
RGB Salient Object Detection
on PASCAL-S

HVS-Inspired Signal Degradation Network for Just Noticeable Difference Estimation
However, they have a major drawback that the generated JND is assessed in the real-world signal domain instead of in the perceptual domain in the human brain.
Investigating Efficiently Extending Transformers for Long Input Summarization
While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge.
 Ranked #2 on
Long-range modeling
on SCROLLS
(GovRep metric)
Ranked #2 on
Long-range modeling
on SCROLLS
(GovRep metric)

Neural Contourlet Network for Monocular 360 Depth Estimation
For a monocular 360 image, depth estimation is a challenging because the distortion increases along the latitude.
 Ranked #8 on
Depth Estimation
on Stanford2D3D Panoramic
Ranked #8 on
Depth Estimation
on Stanford2D3D Panoramic
SMART: Sentences as Basic Units for Text Evaluation
Specifically, We treat sentences as basic units of matching instead of tokens, and use a sentence matching function to soft-match candidate and reference sentences.

SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
Particularly, SiRi conveys a significant principle to the research of visual grounding, i. e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly.

BCS-Net: Boundary, Context and Semantic for Automatic COVID-19 Lung Infection Segmentation from CT Images
The spread of COVID-19 has brought a huge disaster to the world, and the automatic segmentation of infection regions can help doctors to make diagnosis quickly and reduce workload.
Deep Rotation Correction without Angle Prior
To this end, we leverage a neural network to predict the optical flows that can warp the tilted images to be perceptually horizontal.
Complementary Bi-directional Feature Compression for Indoor 360° Semantic Segmentation with Self-distillation
In this paper, we combine the two different representations and propose a novel 360{\deg} semantic segmentation solution from a complementary perspective.


FishFormer: Annulus Slicing-based Transformer for Fisheye Rectification with Efficacy Domain Exploration
To leverage these two characteristics, we introduced Fishformer that processes the fisheye image as a sequence to enhance global and local perception.
FisheyeEX: Polar Outpainting for Extending the FoV of Fisheye Lens
For the distortion synthesis, we propose a spiral distortion-aware perception module, in which the learning path keeps consistent with the distortion prior of the fisheye image.

JNMR: Joint Non-linear Motion Regression for Video Frame Interpolation
Video frame interpolation (VFI) aims to generate predictive frames by warping learnable motions from the bidirectional historical references.
TALM: Tool Augmented Language Models
Transformer based language models (LMs) demonstrate increasing performance with scale across a wide variety of tasks.
Global-and-Local Collaborative Learning for Co-Salient Object Detection
In this paper, we propose a global-and-local collaborative learning architecture, which includes a global correspondence modeling (GCM) and a local correspondence modeling (LCM) to capture comprehensive inter-image corresponding relationship among different images from the global and local perspectives.

Cylin-Painting: Seamless {360\textdegree} Panoramic Image Outpainting and Beyond
Motivated by this analysis, we present a Cylin-Painting framework that involves meaningful collaborations between inpainting and outpainting and efficiently fuses the different arrangements, with a view to leveraging their complementary benefits on a seamless cylinder.
Towards Reliable Image Outpainting: Learning Structure-Aware Multimodal Fusion with Depth Guidance
Concretely, we propose a Depth-Guided Outpainting Network to model different feature representations of two modalities and learn the structure-aware cross-modal fusion.
A Well-Composed Text is Half Done! Composition Sampling for Diverse Conditional Generation
We propose Composition Sampling, a simple but effective method to generate diverse outputs for conditional generation of higher quality compared to previous stochastic decoding strategies.
A Context-Aware Feature Fusion Framework for Punctuation Restoration
To accomplish the punctuation restoration task, most existing approaches focused on leveraging extra information (e. g., part-of-speech tags) or addressing the class imbalance problem.
Distortion-Tolerant Monocular Depth Estimation On Omnidirectional Images Using Dual-cubemap
It comprises two modules: Dual-Cubemap Depth Estimation (DCDE) module and Boundary Revision (BR) module.

PanoFormer: Panorama Transformer for Indoor 360 Depth Estimation
In particular, we divide patches on the spherical tangent domain into tokens to reduce the negative effect of panoramic distortions.
Ranked #4 on
Depth Estimation
on Stanford2D3D Panoramic
Multi-modal Graph Learning for Disease Prediction
For disease prediction tasks, most existing graph-based methods tend to define the graph manually based on specified modality (e. g., demographic information), and then integrated other modalities to obtain the patient representation by Graph Representation Learning (GRL).
Improving Neural ODEs via Knowledge Distillation
We propose a new training based on knowledge distillation to construct more powerful and robust Neural ODEs fitting image recognition tasks.
Deep Rectangling for Image Stitching: A Learning Baseline
In this paper, we address these issues by proposing the first deep learning solution to image rectangling.
ACTIVE:Augmentation-Free Graph Contrastive Learning for Partial Multi-View Clustering
In this paper, we propose an augmentation-free graph contrastive learning framework, namely ACTIVE, to solve the problem of partial multi-view clustering.
Toward a More Populous Online Platform: The Economic Impacts of Compensated Reviews
In this paper, we study the effect of compensated reviews on non-compensated reviews by utilizing online reviews on 1, 240 auto shipping companies over a ten-year period from a transportation website.

Trustworthy Knowledge Graph Completion Based on Multi-sourced Noisy Data
In this paper, we propose a new trustworthy method that exploits facts for a KG based on multi-sourced noisy data and existing facts in the KG.
Auto-Weighted Layer Representation Based View Synthesis Distortion Estimation for 3-D Video Coding
Experimental results show that the VSD can be accurately estimated with the weights learnt by the nonlinear mapping function once its associated S-VSDs are available.
FPPN: Future Pseudo-LiDAR Frame Prediction for Autonomous Driving
LiDAR sensors are widely used in autonomous driving due to the reliable 3D spatial information.

Incomplete Multi-view Clustering via Cross-view Relation Transfer
In this paper, we consider the problem of multi-view clustering on incomplete views.
RRNet: Relational Reasoning Network with Parallel Multi-scale Attention for Salient Object Detection in Optical Remote Sensing Images
Salient object detection (SOD) for optical remote sensing images (RSIs) aims at locating and extracting visually distinctive objects/regions from the optical RSIs.
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
For the cross-modality interaction in feature encoder, existing methods either indiscriminately treat RGB and depth modalities, or only habitually utilize depth cues as auxiliary information of the RGB branch.

Dynamic Feature Regularized Loss for Weakly Supervised Semantic Segmentation
In this paper, we propose a new regularized loss which utilizes both shallow and deep features that are dynamically updated in order to aggregate sufficient information to represent the relationship of different pixels.
Weakly supervised Semantic Segmentation
 Weakly-Supervised Semantic Segmentation
Weakly-Supervised Semantic Segmentation
BridgeNet: A Joint Learning Network of Depth Map Super-Resolution and Monocular Depth Estimation
The other is the content guidance bridge (CGBdg) designed for the depth map reconstruction process, which provides the content guidance learned from DSR task for MDE task.
Depth-Aware Multi-Grid Deep Homography Estimation with Contextual Correlation
Homography estimation is an important task in computer vision applications, such as image stitching, video stabilization, and camera calibration.
Multi-modal Graph Learning for Disease Prediction
However, it is not easy for these approaches to generalize to unseen samples.
Unsupervised Deep Image Stitching: Reconstructing Stitched Features to Images
Even compared with the supervised solutions, our image stitching quality is still preferred by users.
Double Low-Rank Representation With Projection Distance Penalty for Clustering
This paper presents a novel, simple yet robust self-representation method, i. e., Double Low-Rank Representation with Projection Distance penalty (DLRRPD) for clustering.
Affinity Attention Graph Neural Network for Weakly Supervised Semantic Segmentation
More importantly, our approach can be readily applied to bounding box supervised instance segmentation task or other weakly supervised semantic segmentation tasks, with state-of-the-art or comparable performance among almot all weakly supervised tasks on PASCAL VOC or COCO dataset.
Consistent Multiple Graph Embedding for Multi-View Clustering
Specifically, a multiple graph auto-encoder(M-GAE) is designed to flexibly encode the complementary information of multi-view data using a multi-graph attention fusion encoder.
Seeing All From a Few: Nodes Selection Using Graph Pooling for Graph Clustering
This paper is the first attempt to employ graph pooling technique for node clustering and we propose a novel dual graph embedding network (DGEN), which is designed as a two-step graph encoder connected by a graph pooling layer to learn the graph embedding.
Auto-weighted low-rank representation for clustering
In this paper, a novel unsupervised low-rank representation model, i. e., Auto-weighted Low-Rank Representation (ALRR), is proposed to construct a more favorable similarity graph (SG) for clustering.
Planning with Learned Entity Prompts for Abstractive Summarization
Moreover, we demonstrate empirically that planning with entity chains provides a mechanism to control hallucinations in abstractive summaries.
Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
Depth maps obtained by commercial depth sensors are always in low-resolution, making it difficult to be used in various computer vision tasks.
Progressively Complementary Network for Fisheye Image Rectification Using Appearance Flow
We embed a correction layer in skip-connection and leverage the appearance flows in different layers to pre-correct the image features.
Margin Preserving Self-paced Contrastive Learning Towards Domain Adaptation for Medical Image Segmentation
To bridge the gap between the source and target domains in unsupervised domain adaptation (UDA), the most common strategy puts focus on matching the marginal distributions in the feature space through adversarial learning.
Adversarial Graph Disentanglement
For them, a component-specific aggregation approach is proposed to achieve micro-disentanglement by inferring latent components that cause the links between nodes.
Just Noticeable Difference for Deep Machine Vision
Experimental results on image classification demonstrate that we successfully find the JND for deep machine vision.

Image Splicing Detection, Localization and Attribution via JPEG Primary Quantization Matrix Estimation and Clustering
We assume that both the spliced regions and the background image have undergone a double JPEG compression, and use a local estimate of the primary quantization matrix to distinguish between spliced regions taken from different sources.
Efficient video integrity analysis through container characterization
Furthermore, it is capable of correctly identifying the operating system of the source device for most of the tampered videos.
Multi-Level Curriculum for Training a Distortion-Aware Barrel Distortion Rectification Model
In this paper, inspired by the curriculum learning, we analyze the barrel distortion rectification task in a progressive and meaningful manner.
Towards Complete Scene and Regular Shape for Distortion Rectification by Curve-Aware Extrapolation
To our knowledge, we are the first to tackle the challenging rectification via outpainting, and our curve-aware strategy can reach a rectification construction with complete content and regular shape.
Learning Edge-Preserved Image Stitching from Large-Baseline Deep Homography
In this paper, we propose an image stitching learning framework, which consists of a large-baseline deep homography module and an edge-preserved deformation module.
Towards Natural Robustness Against Adversarial Examples
Thus, Neural ODEs have natural robustness against adversarial examples.
Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images
Despite the remarkable advances in visual saliency analysis for natural scene images (NSIs), salient object detection (SOD) for optical remote sensing images (RSIs) still remains an open and challenging problem.
CoADNet: Collaborative Aggregation-and-Distribution Networks for Co-Salient Object Detection
In the first stage, we propose a group-attentional semantic aggregation module that models inter-image relationships to generate the group-wise semantic representations.
Learning Deep Interleaved Networks with Asymmetric Co-Attention for Image Restoration
In this paper, we present a deep interleaved network (DIN) that learns how information at different states should be combined for high-quality (HQ) images reconstruction.

Mining Generalized Features for Detecting AI-Manipulated Fake Faces
Recently, AI-manipulated face techniques have developed rapidly and constantly, which has raised new security issues in society.
LID 2020: The Learning from Imperfect Data Challenge Results
The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training.
Taking Modality-free Human Identification as Zero-shot Learning
There have been numerous methods proposed for human identification, such as face identification, person re-identification, and gait identification.
A Parallel Down-Up Fusion Network for Salient Object Detection in Optical Remote Sensing Images
In this paper, we propose a novel Parallel Down-up Fusion network (PDF-Net) for SOD in optical RSIs, which takes full advantage of the in-path low- and high-level features and cross-path multi-resolution features to distinguish diversely scaled salient objects and suppress the cluttered backgrounds.
A Deep Ordinal Distortion Estimation Approach for Distortion Rectification
Our key insight is that distortion rectification can be cast as a problem of learning an ordinal distortion from a single distorted image.
Pseudo-LiDAR Point Cloud Interpolation Based on 3D Motion Representation and Spatial Supervision
Pseudo-LiDAR point cloud interpolation is a novel and challenging task in the field of autonomous driving, which aims to address the frequency mismatching problem between camera and LiDAR.
SEAL: Segment-wise Extractive-Abstractive Long-form Text Summarization
Most prior work in the sequence-to-sequence paradigm focused on datasets with input sequence lengths in the hundreds of tokens due to the computational constraints of common RNN and Transformer architectures.
Referring Image Segmentation by Generative Adversarial Learning
To this end, we propose to train the referring image segmentation model in a generative adversarial fashion, which well addresses the distribution similarity problem.
Fast Template Matching and Update for Video Object Tracking and Segmentation
Specifically, the reinforcement learning agent learns to decide whether to update the target template according to the quality of the predicted result.
From Anchor Generation to Distribution Alignment: Learning a Discriminative Embedding Space for Zero-Shot Recognition
In zero-shot learning (ZSL), the samples to be classified are usually projected into side information templates such as attributes.

Concurrently Extrapolating and Interpolating Networks for Continuous Model Generation
Most deep image smoothing operators are always trained repetitively when different explicit structure-texture pairs are employed as label images for each algorithm configured with different parameters.
Deep Optimized Multiple Description Image Coding via Scalar Quantization Learning
In this paper, we introduce a deep multiple description coding (MDC) framework optimized by minimizing multiple description (MD) compressive loss.
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Recent work pre-training Transformers with self-supervised objectives on large text corpora has shown great success when fine-tuned on downstream NLP tasks including text summarization.
 Ranked #1 on
Abstractive Text Summarization
on AESLC
Ranked #1 on
Abstractive Text Summarization
on AESLC
To See in the Dark: N2DGAN for Background Modeling in Nighttime Scene
Due to the deteriorated conditions of \mbox{illumination} lack and uneven lighting, nighttime images have lower contrast and higher noise than their daytime counterparts of the same scene, which limits seriously the performances of conventional background modeling methods.
Distribution-induced Bidirectional Generative Adversarial Network for Graph Representation Learning
Graph representation learning aims to encode all nodes of a graph into low-dimensional vectors that will serve as input of many compute vision tasks.
Generative Adversarial Network
Graph Representation Learning
Progressive Sample Mining and Representation Learning for One-Shot Person Re-identification with Adversarial Samples
To tackle this problem, we propose to iteratively guess pseudo labels for the unlabeled image samples, which are later used to update the re-identification model together with the labelled samples.

ATZSL: Defensive Zero-Shot Recognition in the Presence of Adversaries
In this paper, we take an initial attempt, and propose a generic formulation to provide a systematical solution (named ATZSL) for learning a robust ZSL model.


ProLFA: Representative Prototype Selection for Local Feature Aggregation
Given a set of hand-crafted local features, acquiring a global representation via aggregation is a promising technique to boost computational efficiency and improve task performance.
Hierarchical Prototype Learning for Zero-Shot Recognition
Specifically, HPL is able to obtain discriminability on both seen and unseen class domains by learning visual prototypes respectively under the transductive setting.
Convolutional Prototype Learning for Zero-Shot Recognition
The key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary class attribute vectors.
PLIN: A Network for Pseudo-LiDAR Point Cloud Interpolation
In this paper, we propose a novel Pseudo-LiDAR interpolation network (PLIN) to increase the frequency of LiDAR sensors.
Segmentation Mask Guided End-to-End Person Search
Person search aims to search for a target person among multiple images recorded by multiple surveillance cameras, which faces various challenges from both pedestrian detection and person re-identification.

Primary quantization matrix estimation of double compressed JPEG images via CNN
Available model-based techniques for the estimation of the primary quantization matrix in double-compressed JPEG images work only under specific conditions regarding the relationship between the first and second compression quality factors, and the alignment of the first and second JPEG compression grids.
Edge Heuristic GAN for Non-uniform Blind Deblurring
Non-uniform blur, mainly caused by camera shake and motions of multiple objects, is one of the most common causes of image quality degradation.
Architecture Selection via the Trade-off Between Accuracy and Robustness
We provide a general framework for characterizing the trade-off between accuracy and robustness in supervised learning.
EA-LSTM: Evolutionary Attention-based LSTM for Time Series Prediction
To address this issue, an evolutionary attention-based LSTM training with competitive random search is proposed for multivariate time series prediction.
Correlation Filter Selection for Visual Tracking Using Reinforcement Learning
In this paper, we propose a novel approach to address the correlation filter update problem.
Deep Multiple Description Coding by Learning Scalar Quantization
Secondly, two entropy estimation networks are learned to estimate the informative amounts of the quantized tensors, which can further supervise the learning of multiple description encoder network to represent the input image delicately.
Paragraph-level Neural Question Generation with Maxout Pointer and Gated Self-attention Networks
Long text has posed challenges for sequence to sequence neural models in question generation {--} worse performances were reported if using the whole paragraph (with multiple sentences) as the input.
Devil in the Details: Towards Accurate Single and Multiple Human Parsing
Human parsing has received considerable interest due to its wide application potentials.
 Ranked #2 on
Person Re-Identification
on Market-1501-C
Ranked #2 on
Person Re-Identification
on Market-1501-C

Virtual Codec Supervised Re-Sampling Network for Image Compression
In order to train RSN network and IDN network together in an end-to-end fashion, our VCN network intimates projection from the re-sampled vectors to the IDN-decoded image.

Adversarial Attacks and Defences Competition
To accelerate research on adversarial examples and robustness of machine learning classifiers, Google Brain organized a NIPS 2017 competition that encouraged researchers to develop new methods to generate adversarial examples as well as to develop new ways to defend against them.
Security Consideration For Deep Learning-Based Image Forensics
Instead of improving it, in this paper, the safety of deep learning based methods in the field of image forensics is taken into account.
Non-Local Graph-Based Prediction For Reversible Data Hiding In Images
If sufficiently smooth, we pose a maximum a posteriori (MAP) problem using either a quadratic Laplacian regularizer or a graph total variation (GTV) term as signal prior.
Secure Detection of Image Manipulation by means of Random Feature Selection
We address the problem of data-driven image manipulation detection in the presence of an attacker with limited knowledge about the detector.
Cryptography and Security
Mixed-Resolution Image Representation and Compression with Convolutional Neural Networks
Firstly, given one input image, feature description neural network (FDNN) is used to generate a new representation of this image, so that this image representation can be more efficiently compressed by standard codec, as compared to the input image.
Multiple Description Convolutional Neural Networks for Image Compression
Thirdly, multiple description virtual codec network (MDVCN) is proposed to bridge the gap between MDGN network and MDRN network in order to train an end-to-end MDC framework.
Learning a Virtual Codec Based on Deep Convolutional Neural Network to Compress Image
Due to the challenge of directly learning a non-linear function for a standard codec based on convolutional neural network, we propose to learn a virtual codec neural network to approximate the projection from the valid description image to the post-processed compressed image, so that the gradient could be efficiently back-propagated from the post-processing neural network to the feature description neural network during training.

Simultaneously Color-Depth Super-Resolution with Conditional Generative Adversarial Network
Firstly, given the low-resolution depth image and low-resolution color image, a generative network is proposed to leverage mutual information of color image and depth image to enhance each other in consideration of the geometry structural dependency of color-depth image in the same scene.

Local Activity-tuned Image Filtering for Noise Removal and Image Smoothing
Both frameworks employ the division of gradient and the local activity measurement to achieve noise removal.

Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach
We investigate a principle way to progressively mine discriminative object regions using classification networks to address the weakly-supervised semantic segmentation problems.


Source Camera Identification Based On Content-Adaptive Fusion Network
In this paper, we propose a solution to identify the source camera of the small-size images: content-adaptive fusion network.
A New Evaluation Protocol and Benchmarking Results for Extendable Cross-media Retrieval
Additionally, a trivial solution, \ie, directly using the predicted class label for cross-media retrieval, is tested.

Camera Fingerprint: A New Perspective for Identifying User's Identity
The underlying assumption is that multiple accounts belonging to the same person contain the same or similar camera fingerprint information.
STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
Then, a better network called Enhanced-DCNN is learned with supervision from the predicted segmentation masks of simple images based on the Initial-DCNN as well as the image-level annotations.
Indexing of CNN Features for Large Scale Image Search
The convolutional neural network (CNN) features can give a good description of image content, which usually represent images with unique global vectors.
Modality-dependent Cross-media Retrieval
Specifically, by jointly optimizing the correlation between images and text and the linear regression from one modal space (image or text) to the semantic space, two couples of mappings are learned to project images and text from their original feature spaces into two common latent subspaces (one for I2T and the other for T2I).
CNN: Single-label to Multi-label
Convolutional Neural Network (CNN) has demonstrated promising performance in single-label image classification tasks.
Kernel Reconstruction ICA for Sparse Representation
However, ICA is not only sensitive to whitening but also difficult to learn an over-complete basis.
