Temporal Relational Modeling with Self-Supervision for Action Segmentation
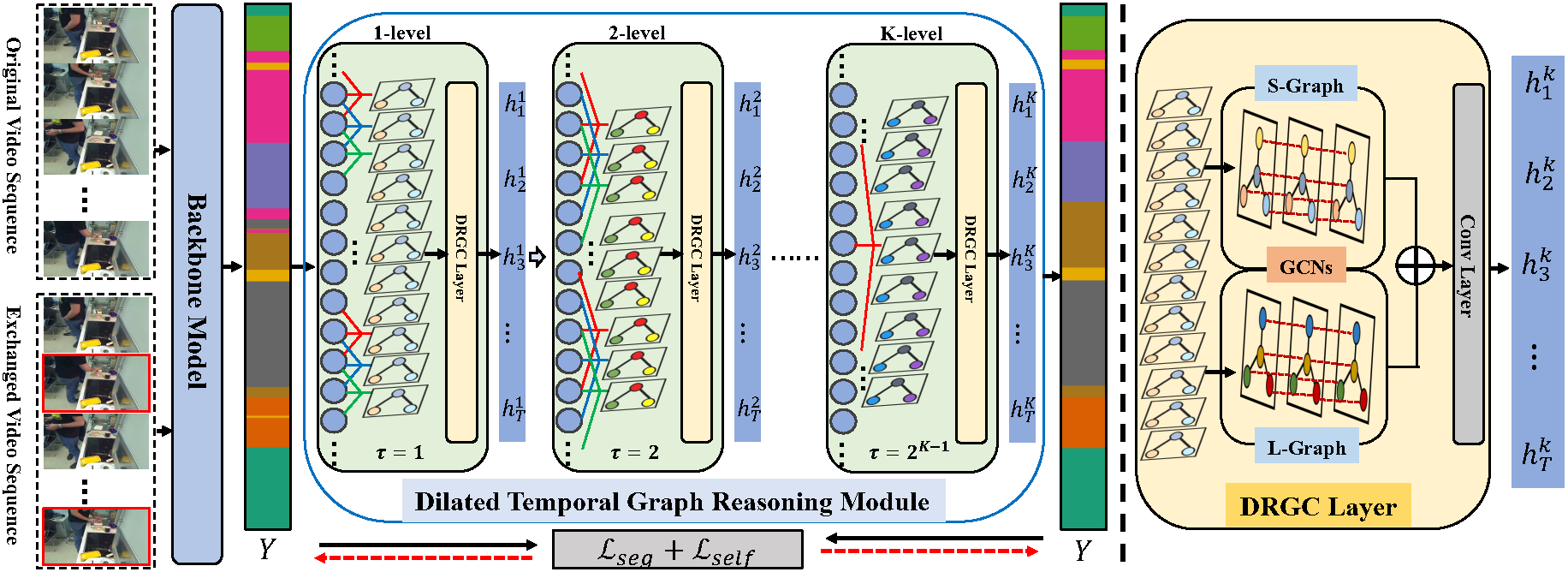
Temporal relational modeling in video is essential for human action understanding, such as action recognition and action segmentation. Although Graph Convolution Networks (GCNs) have shown promising advantages in relation reasoning on many tasks, it is still a challenge to apply graph convolution networks on long video sequences effectively. The main reason is that large number of nodes (i.e., video frames) makes GCNs hard to capture and model temporal relations in videos. To tackle this problem, in this paper, we introduce an effective GCN module, Dilated Temporal Graph Reasoning Module (DTGRM), designed to model temporal relations and dependencies between video frames at various time spans. In particular, we capture and model temporal relations via constructing multi-level dilated temporal graphs where the nodes represent frames from different moments in video. Moreover, to enhance temporal reasoning ability of the proposed model, an auxiliary self-supervised task is proposed to encourage the dilated temporal graph reasoning module to find and correct wrong temporal relations in videos. Our DTGRM model outperforms state-of-the-art action segmentation models on three challenging datasets: 50Salads, Georgia Tech Egocentric Activities (GTEA), and the Breakfast dataset. The code is available at https://github.com/redwang/DTGRM.
PDF Abstract


 Breakfast
Breakfast
 GTEA
GTEA

