Teachers Do More Than Teach: Compressing Image-to-Image Models
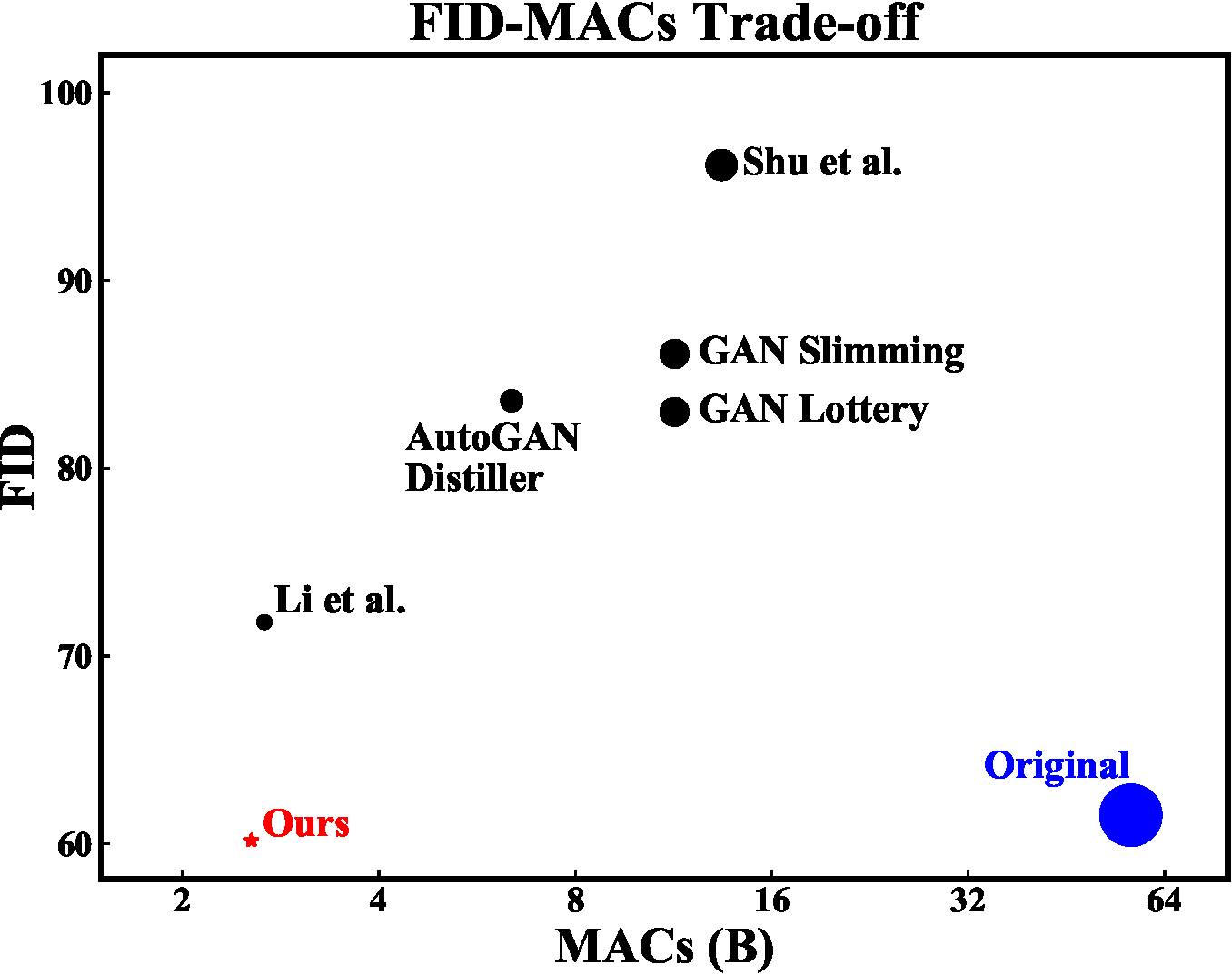
Generative Adversarial Networks (GANs) have achieved huge success in generating high-fidelity images, however, they suffer from low efficiency due to tremendous computational cost and bulky memory usage. Recent efforts on compression GANs show noticeable progress in obtaining smaller generators by sacrificing image quality or involving a time-consuming searching process. In this work, we aim to address these issues by introducing a teacher network that provides a search space in which efficient network architectures can be found, in addition to performing knowledge distillation. First, we revisit the search space of generative models, introducing an inception-based residual block into generators. Second, to achieve target computation cost, we propose a one-step pruning algorithm that searches a student architecture from the teacher model and substantially reduces searching cost. It requires no l1 sparsity regularization and its associated hyper-parameters, simplifying the training procedure. Finally, we propose to distill knowledge through maximizing feature similarity between teacher and student via an index named Global Kernel Alignment (GKA). Our compressed networks achieve similar or even better image fidelity (FID, mIoU) than the original models with much-reduced computational cost, e.g., MACs. Code will be released at https://github.com/snap-research/CAT.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract

 Cityscapes
Cityscapes
