Motion Guided 3D Pose Estimation from Videos
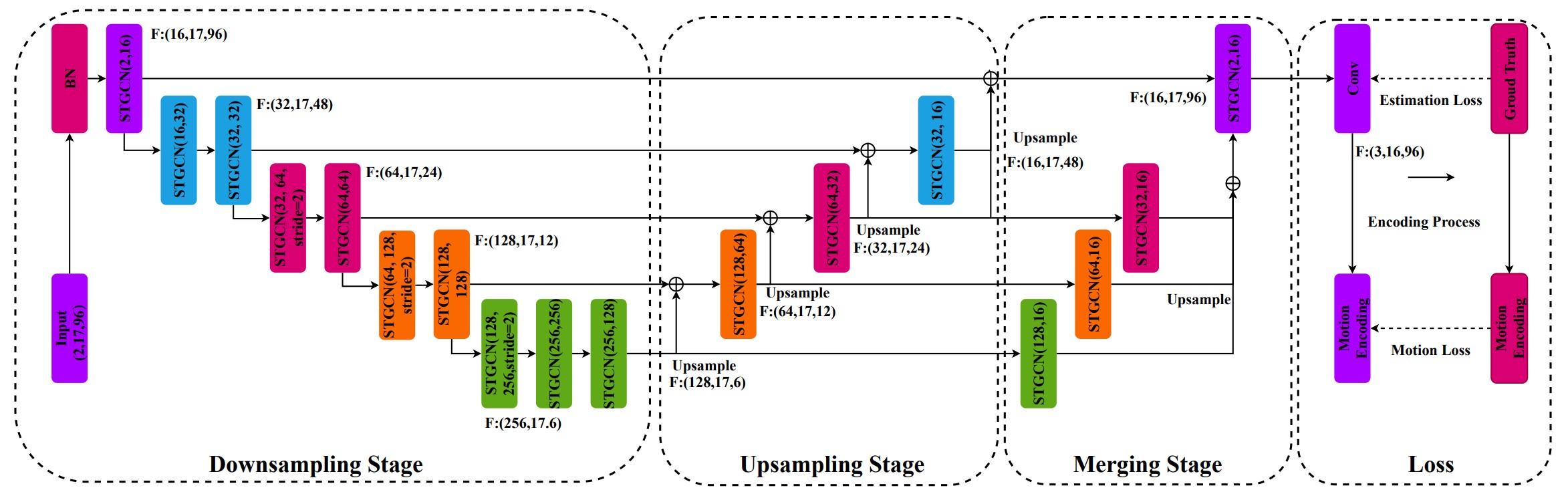
We propose a new loss function, called motion loss, for the problem of monocular 3D Human pose estimation from 2D pose. In computing motion loss, a simple yet effective representation for keypoint motion, called pairwise motion encoding, is introduced. We design a new graph convolutional network architecture, U-shaped GCN (UGCN). It captures both short-term and long-term motion information to fully leverage the additional supervision from the motion loss. We experiment training UGCN with the motion loss on two large scale benchmarks: Human3.6M and MPI-INF-3DHP. Our model surpasses other state-of-the-art models by a large margin. It also demonstrates strong capacity in producing smooth 3D sequences and recovering keypoint motion.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract




 Human3.6M
Human3.6M
 MPI-INF-3DHP
MPI-INF-3DHP

