Exploiting Temporal Contexts with Strided Transformer for 3D Human Pose Estimation
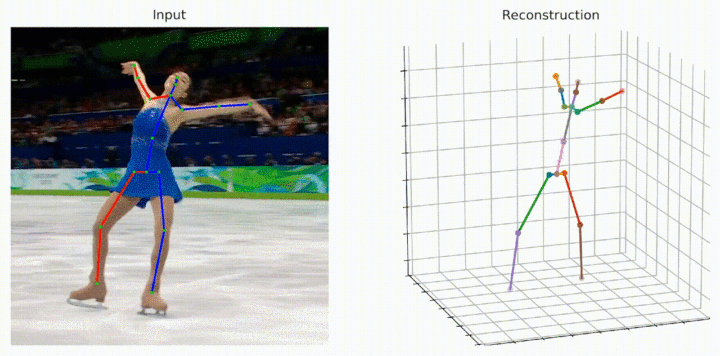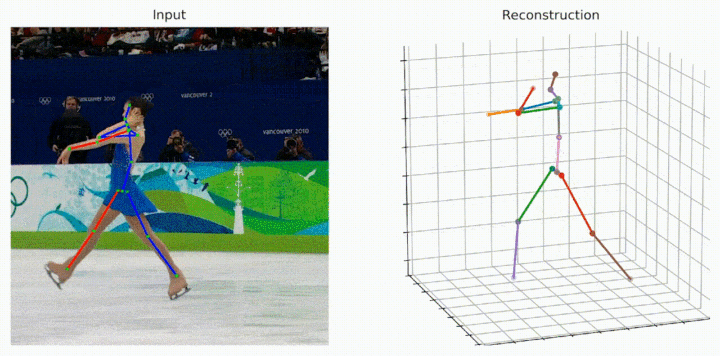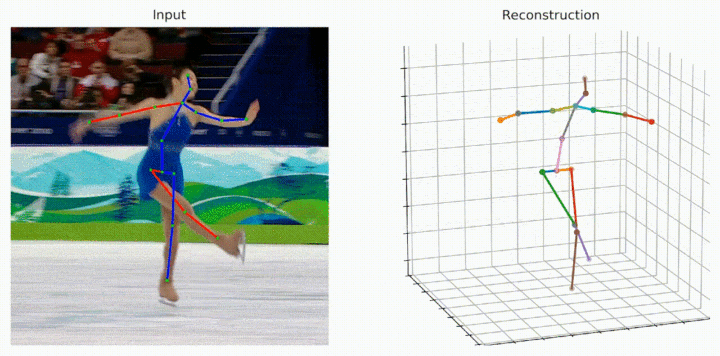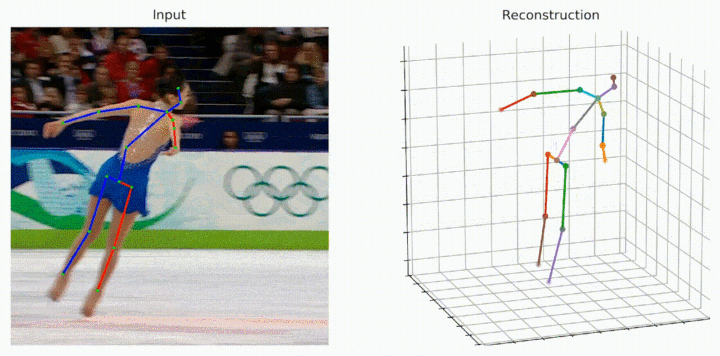
Despite the great progress in 3D human pose estimation from videos, it is still an open problem to take full advantage of a redundant 2D pose sequence to learn representative representations for generating one 3D pose. To this end, we propose an improved Transformer-based architecture, called Strided Transformer, which simply and effectively lifts a long sequence of 2D joint locations to a single 3D pose. Specifically, a Vanilla Transformer Encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce the redundancy of the sequence, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively shrink the sequence length and aggregate information from local contexts. The modified VTE is termed as Strided Transformer Encoder (STE), which is built upon the outputs of VTE. STE not only effectively aggregates long-range information to a single-vector representation in a hierarchical global and local fashion, but also significantly reduces the computation cost. Furthermore, a full-to-single supervision scheme is designed at both full sequence and single target frame scales applied to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision and hence helps produce smoother and more accurate 3D poses. The proposed Strided Transformer is evaluated on two challenging benchmark datasets, Human3.6M and HumanEva-I, and achieves state-of-the-art results with fewer parameters. Code and models are available at \url{https://github.com/Vegetebird/StridedTransformer-Pose3D}.
PDF Abstract



 Human3.6M
Human3.6M

