Learning Spatio-Temporal Transformer for Visual Tracking
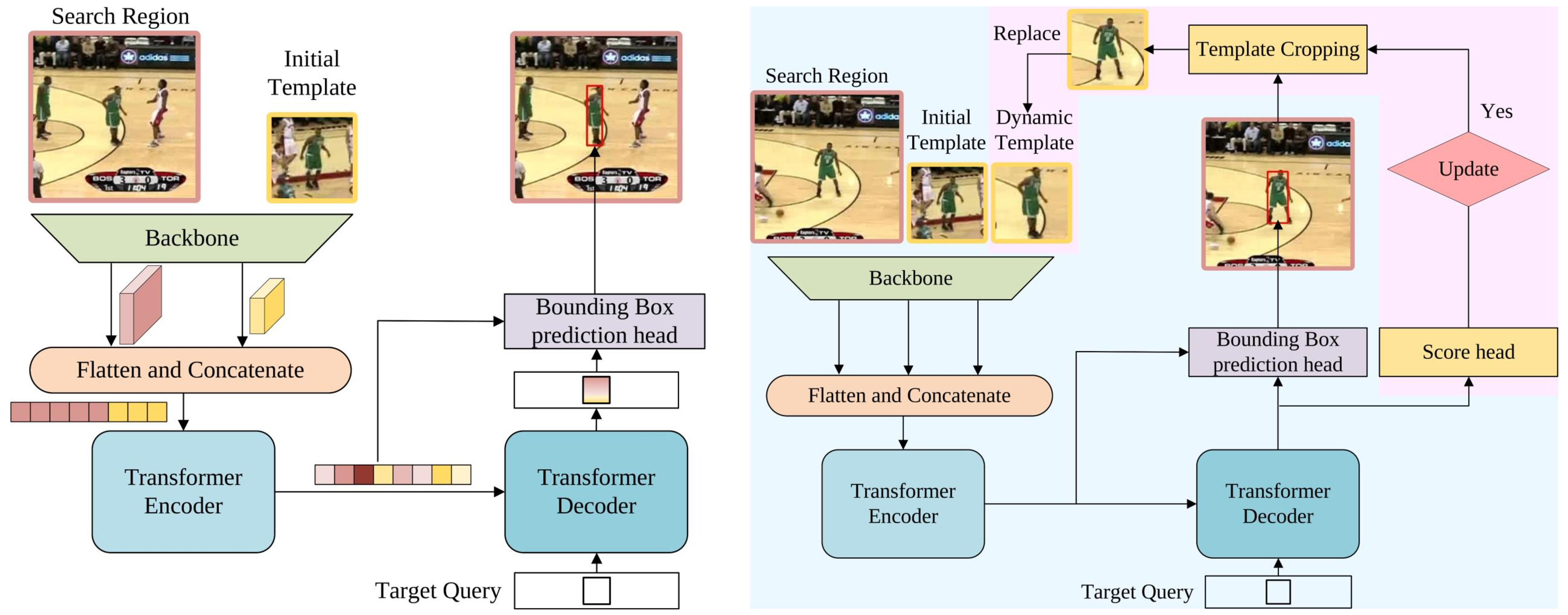
In this paper, we present a new tracking architecture with an encoder-decoder transformer as the key component. The encoder models the global spatio-temporal feature dependencies between target objects and search regions, while the decoder learns a query embedding to predict the spatial positions of the target objects. Our method casts object tracking as a direct bounding box prediction problem, without using any proposals or predefined anchors. With the encoder-decoder transformer, the prediction of objects just uses a simple fully-convolutional network, which estimates the corners of objects directly. The whole method is end-to-end, does not need any postprocessing steps such as cosine window and bounding box smoothing, thus largely simplifying existing tracking pipelines. The proposed tracker achieves state-of-the-art performance on five challenging short-term and long-term benchmarks, while running at real-time speed, being 6x faster than Siam R-CNN. Code and models are open-sourced at https://github.com/researchmm/Stark.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract


 LaSOT
LaSOT
 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
