Decoupled Spatial-Temporal Transformer for Video Inpainting
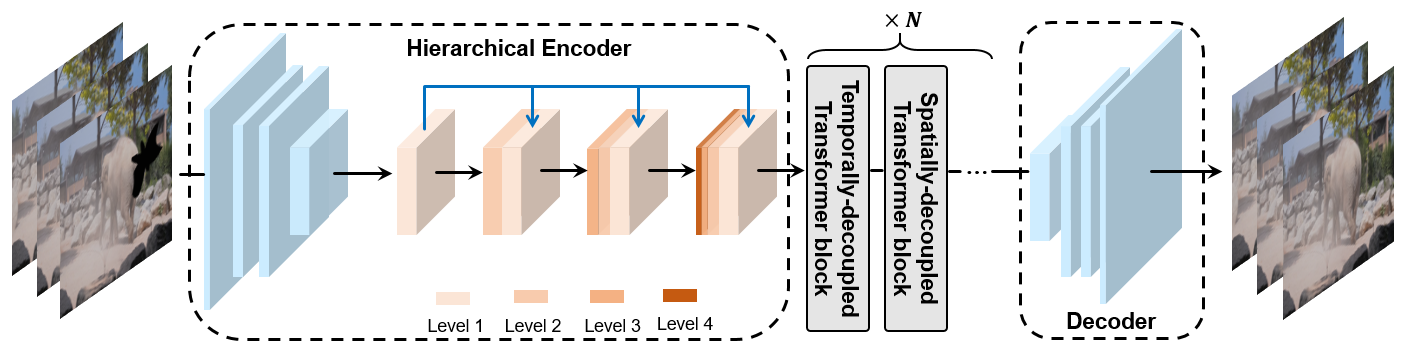
Video inpainting aims to fill the given spatiotemporal holes with realistic appearance but is still a challenging task even with prosperous deep learning approaches. Recent works introduce the promising Transformer architecture into deep video inpainting and achieve better performance. However, it still suffers from synthesizing blurry texture as well as huge computational cost. Towards this end, we propose a novel Decoupled Spatial-Temporal Transformer (DSTT) for improving video inpainting with exceptional efficiency. Our proposed DSTT disentangles the task of learning spatial-temporal attention into 2 sub-tasks: one is for attending temporal object movements on different frames at same spatial locations, which is achieved by temporally-decoupled Transformer block, and the other is for attending similar background textures on same frame of all spatial positions, which is achieved by spatially-decoupled Transformer block. The interweaving stack of such two blocks makes our proposed model attend background textures and moving objects more precisely, and thus the attended plausible and temporally-coherent appearance can be propagated to fill the holes. In addition, a hierarchical encoder is adopted before the stack of Transformer blocks, for learning robust and hierarchical features that maintain multi-level local spatial structure, resulting in the more representative token vectors. Seamless combination of these two novel designs forms a better spatial-temporal attention scheme and our proposed model achieves better performance than state-of-the-art video inpainting approaches with significant boosted efficiency.
PDF Abstract

 DAVIS
DAVIS
 YouTube-VOS 2018
YouTube-VOS 2018
